
Introduction
Today, we're going to explore the concept of running a software company without the need for an operations team or an SRE team. We'll discuss the evolving landscape of operations and its implications for developers. This discussion will be presented from a developer's perspective.
Throughout our conversation, we'll cover various topics, including the transformation of operations over time, its impact on developers, and the advantages of embracing a NoOps strategy. We'll examine how this approach can make it easier for you to hire exceptional developers and gain a competitive advantage. You can watch the full video here.
Operations and the Role of Developers
To kick things off, let's delve into the history of operations and the role developers played in it. Initially, operations involved on-premise technology, where all the servers were housed in a dedicated server room. Developers typically didn't have to physically visit the server room because an operations team was responsible for managing and overseeing the servers. It's often depicted as an ideal scenario, where the server room resembles a picturesque.

Over time, as technology advances and systems grow, various challenges emerge. Equipment breaks down, requiring frequent switching and replacement. As a result, the infrastructure becomes entangled in a complex web of wires, resembling a massive spaghetti junction. Managing such a setup becomes increasingly unmanageable. This is where the presence of a dedicated SRE team or DevOps team becomes crucial. They take charge of maintaining and overseeing this infrastructure. Developers, for the most part, are shielded from directly dealing with these operational complexities. However, it's important to note that maintaining a dedicated operations team can be a costly endeavor.
Managed Data Center
To eliminate the physical management of infrastructure, many companies have transitioned towards utilizing managed data centers. In this setup, you hand over your server configuration to a specialized company that takes care of installation, monitoring, and optimizing its performance. This shift offers several significant advantages for your company. Firstly, you are relieved of the responsibility of maintaining the server's operational state, as well as ensuring physical and digital security within the facility. Additionally, the internet connection provided by these managed data centers is often superior to the standard office connection.
While this approach brings numerous benefits, there are still some drawbacks to consider. Firstly, you are limited to a fixed number of servers. As a developer, you must consider not only writing efficient code but also estimate the number of users or transactions that the system will handle and determine the necessary compute units or servers required. On the operations side, you remain responsible for server upgrades and addressing any component failures. Furthermore, managing the hardware, including BIOS configurations, operating systems, and patches, adds to the operational overhead. Whether this responsibility lies with an operations team or developers, it incurs additional costs for your organization.

Cloud servers
The next stage in the evolution was the emergence of cloud servers, such as EC2, Google VMs, or Azure VMs. These servers offer the significant advantage of being available on-demand. In other words, whenever you require a more powerful compute unit or face increased user demand, you can easily obtain additional servers to meet those needs. I'll also include Kubernetes and other clustering solutions in this category, keeping in mind that this is a simplified overview.
The transition to cloud servers brings significant cost reductions and enhanced flexibility to operations. By eliminating the need for precise demand forecasting, companies gain the ability to dynamically adapt to changing requirements. Whether facing sudden surges in traffic or planning for future growth, cloud servers facilitate seamless scaling up or down to accommodate these demands.
However, even with features like auto-scaling groups, there are still responsibilities to manage, such as defining auto-scaling policies. The question of whether these tasks should be handled by developers or the operations team often sparks debate. It's important to recognize that developers may need to shoulder additional responsibilities beyond coding, especially when it comes to optimizing server capacity and ensuring smooth operational performance.

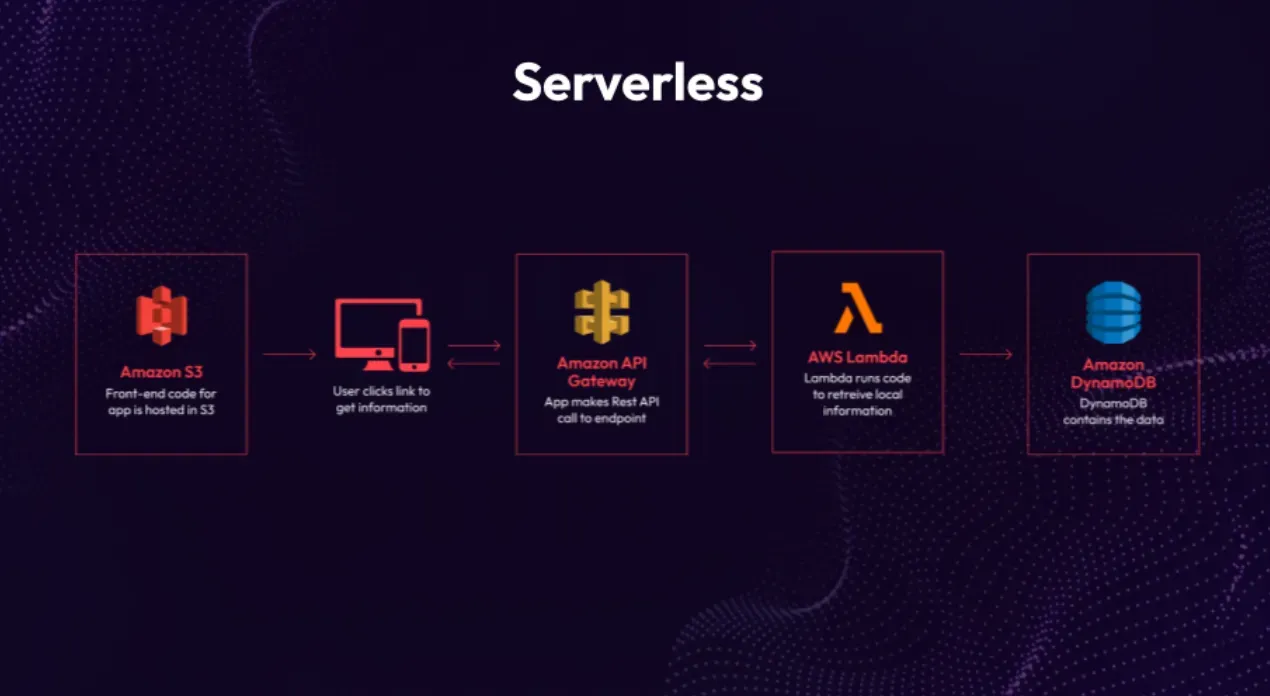
Serverless
Developers also face the challenge of ensuring redundancy and failover in their infrastructure. It's important to consider what happens if the server hosting the database crashes. Is the data properly backed up? Is there redundancy in place? Managing multiple servers and optimizing their performance can be a complex undertaking. Additionally, networking plays a crucial role. Are there Virtual Private Clouds (VPCs) established? Are subnets and NAT gateways configured appropriately? Setting up the networking infrastructure is essential for provisioning and serving applications while maintaining security and avoiding vulnerabilities that could be exploited by attackers. These tasks add an extra layer of complexity that developers must address.
Let's explore the next significant advancement: the shift to serverless architecture. This represents a major transformation, as it embraces true on-demand capabilities. With services like Lambda, AWS automatically scales up instances or Lambda functions to handle increased request volumes. Networking in serverless is simplified as well. Lambdas and Dynamo tables are inherently isolated from the external environment, unless explicitly configured to allow access through API gateways or Lambda URLs. This enhanced security makes it extremely challenging for unauthorized parties to access your code.
Serverless architecture offers several notable advantages. For instance, DynamoDB provides built-in redundancy across availability zones. In the event of a data center failure in your region, your data remains accessible through other availability zones. This means developers and operations engineers no longer need to intricately plan and implement availability zone redundancy, greatly simplifying their workload.
Efficiency and Overcoming Hurdles in Serverless Architecture
Now, serverless architecture has revolutionized how developers can build solutions without the need for extensive operations expertise. However, it does come with a few challenges that critics often highlight. One such challenge is determining the optimal size for each Lambda function. As we discussed in a previous talk by Nikhill, finding the perfect size can be a difficult task, despite various approaches available. Another challenge is cold starts. When a Lambda function starts up, there is an initialization time for each instance, especially the first time it's cold. Resolving this issue is crucial.
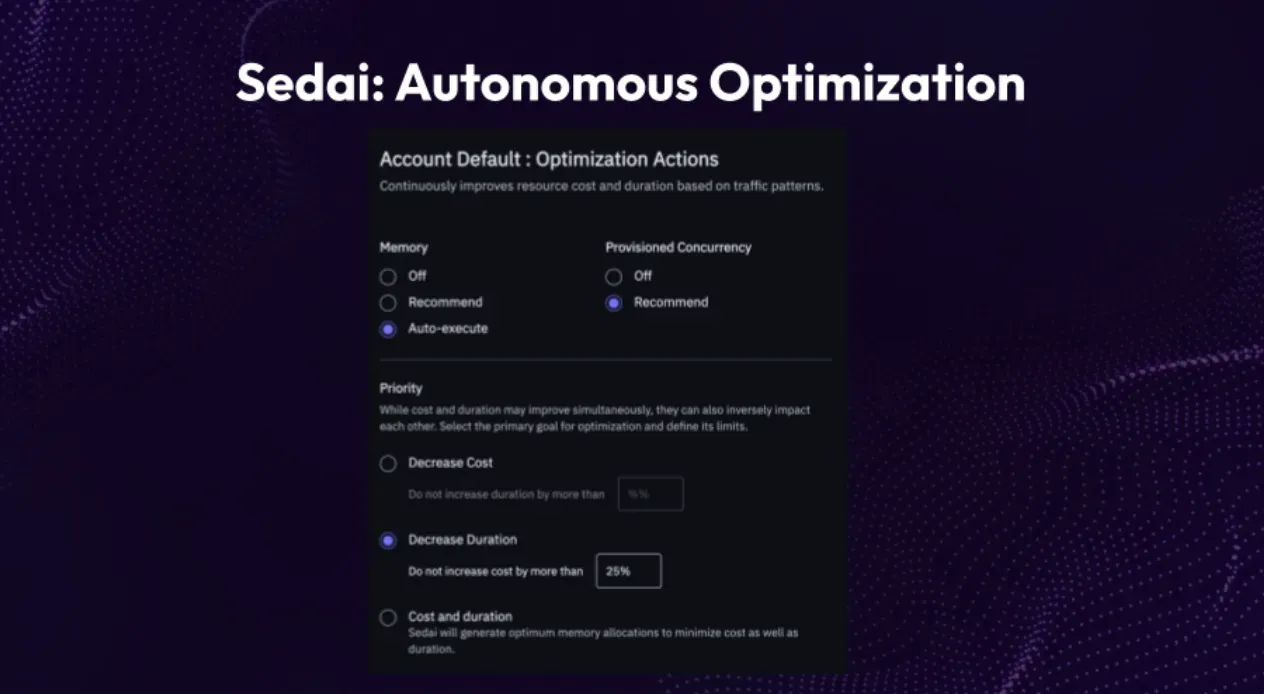
To address these challenges, we can leverage the Sedai platform, which autonomously optimizes Lambda functions by adjusting their memory capacity. In the example shown on the screen, we observe a significant improvement. The average duration decreased by 94%, from over 3.9 seconds to less than 0.2 seconds, while also reducing the overall resource usage. This optimization is achieved through the Sedai platform's autonomous monitoring of Lambdas and providing suggestions for memory capacity adjustments. In this specific case, the memory was increased by 50%, from 1.54 to 2.3 gigabytes, resulting in significant savings. Since implementing this optimization, the Lambda runtime has been reduced by one day and 11 hours, leading to substantial cost savings and an improved user experience.
Autonomous Optimization
When optimizing Lambdas with Sedai, you have the option to specify whether you prioritize speed and performance or cost optimization. Sedai can automatically execute the optimization based on its recommendations, or you can review the recommendations and manually apply them. At the bottom of the Sedai platform, there is a priority setting that allows you to fine-tune the optimization. For Lambdas where user experience is crucial, such as a shopping checkout cart, you may prioritize decreasing the duration. However, it's important to strike a balance, as you don't want to make it excessively fast and costly. You can set a constraint to make it as quick as possible while limiting the total cost increase to a maximum of 25%.
On the other hand, for batch processes like image resizing, you might prioritize affordability. In this case, you can focus on reducing the cost while setting a constraint to prevent a significant increase in processing time, for example, no more than 40%.
Optimizing Lambdas and Eliminating Cold Starts with Sedai
Now that you're familiar with optimizing Lambdas in the Sedai platform, let's explore how Sedai addresses another common issue: cold starts. In the example displayed on the screen, each horizontal row represents an instance of your Lambda, and multiple requests are being made. When the first request is received, it triggers the installation of a new Lambda instance, which involves downloading the code and setting up the runtime. This initial setup, known as a cold start, depends on factors like the size of your code repository, runtime configuration, and other considerations.
If a second request arrives while the first instance is still busy, it also experiences a cold start as it initializes. However, with Sedai, we have an automated mechanism to proactively trigger the initialization of Lambda functions before any requests are received. This means that when the first request comes in, the Lambda instance is already initialized and ready to execute, resulting in faster response times without the additional delay caused by cold starts.

Sedai Provisioned Capacity
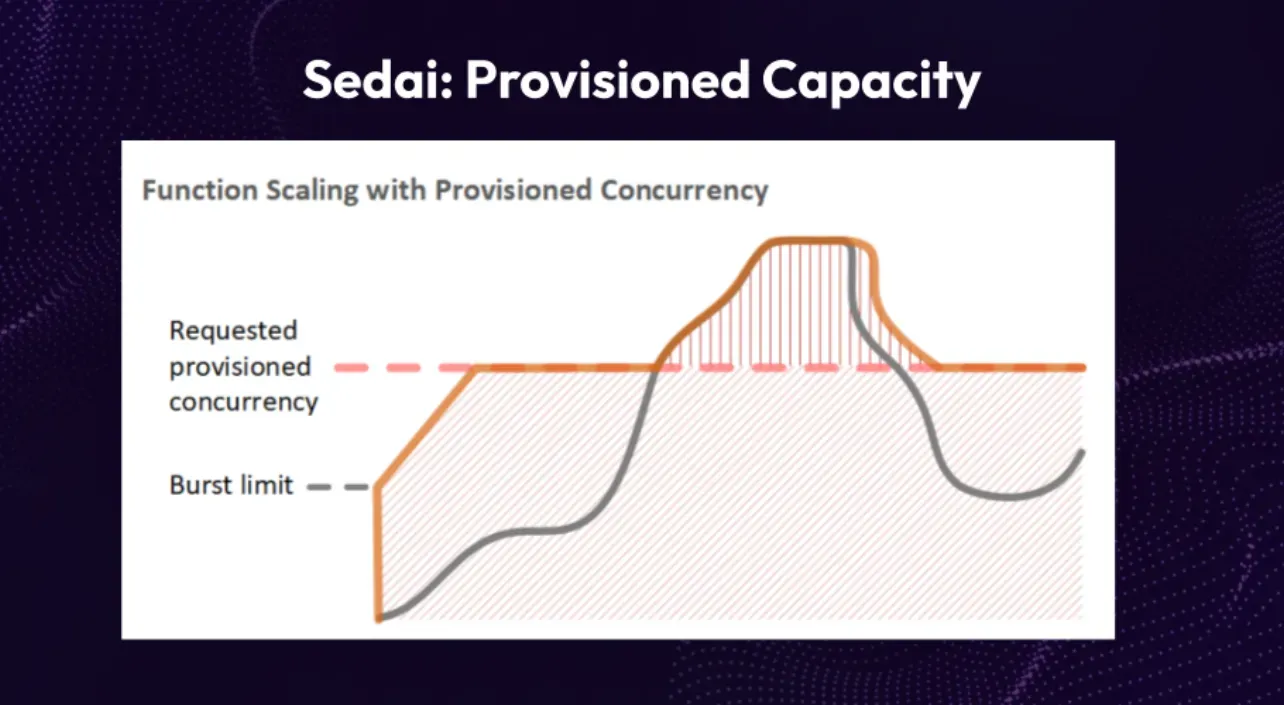
One important aspect to consider is provisioned capacity, a valuable feature within Lambda. With provisioned capacity, you can ensure that a set number of Lambda instances are constantly prepared and ready for action. By specifying that you want, let's say, five instances of a Lambda function to always be available and initialized, you eliminate the delay caused by cold starts when receiving requests. This means that as soon as a request arrives, or even if five requests come simultaneously, the Lambdas are already primed and can instantly process them.
Moreover, provisioned capacity offers an additional advantage. It guarantees that there will always be at least five instances of your Lambdas accessible, which is particularly useful if you're approaching the limit of your overall account-level Lambda provisioning. Determining the optimal value for provisioned capacity can often be challenging, but through Sedai, this complexity is resolved. Sedai autonomously assesses and determines the most suitable provisioned capacity for all your Lambdas, making the process seamless and effortless for you. Another benefit of provisioned capacity is the assurance that your Lambdas will consistently meet the demands of your workload. By having a predetermined number of initialized instances, you can confidently handle spikes in traffic or high request volumes without worrying about performance bottlenecks.
Additionally, Sedai simplifies the management of provisioned capacity by automatically calculating and implementing the optimal value for your Lambdas. This alleviates the burden of manually fine-tuning and ensures that your functions are always equipped with the right amount of resources, maximizing efficiency and responsiveness.
Business Impact
Let's delve into the actual business implications of all this processing power. The fundamental question for your business is: Who takes care of your operational tasks? Typically, you have two main options: either your developers handle it themselves or you employ a dedicated operations team. In this discussion, we'll focus on the perspective of developers.
As a developer, your time spent on actual coding is often limited. Research suggests that, on average, you dedicate only four hours per day to writing code. The remaining time is consumed by various business-related tasks such as code reviews and other daily responsibilities. If an additional hour is added for operations tasks, your developer efficiency can plummet by 25%, which is a significant decrease.
Now, if your priority is to keep your developers as efficient as possible, you might consider hiring an operations team. However, you'll quickly realize that employing a DevOps engineer can cost an average of $105,000. This amount is substantial and equivalent to running the largest Lambda, with a size of 10 gigabytes, continuously for nearly 20 years. That's even longer than the total time AWS has been in existence. Clearly, this approach doesn't provide an ideal cost-effective solution.
Fortunately, there's a third option available when utilizing serverless architecture—eliminating the need for any operations tasks altogether. By selecting sensible default sizes for your Lambdas and forgoing provisioned capacity, you can embrace the occasional cold start trade-off. Although this may be acceptable for startups aiming for rapid development, it comes with performance costs. Cold starts can impact response times, and optimizing your Lambdas by increasing memory allocation, as seen earlier, can result in significant reductions in both duration and resource usage—sometimes up to 90%. Furthermore, certain Lambdas may spend a significant amount of time waiting for a second request or interacting with third-party services. In such cases, these Lambdas can be optimized by reducing their memory allocation and, consequently, saving up to 16 times the costs without affecting the overall duration.
Provisioned Capacity and Release Intelligence with Sedai
Lastly, the Sedai platform offers an additional valuable feature known as release intelligence. With release intelligence, Sedai actively monitors your Lambdas both before and after a deployment. It provides you with quantitative feedback on whether there has been an improvement or a decline in system performance. For example, it can easily identify if one of your Lambdas is running slower than before. This capability is an excellent added bonus, as it allows you to stay informed about the performance impact of your system changes, ensuring you can make informed decisions and swiftly address any issues that arise.

Summary
In the evolving software hosting landscape, the shift from on-premises to cloud and serverless environments has simplified operations tasks. However, challenges like Lambda sizing and cold starts persist in serverless architecture. This is where Sedai comes in, offering autonomous solutions to tackle these challenges and lighten the developer's workload.
Compared to traditional EC2-based approaches, developing with serverless architecture has proven to save developers significant time. With prebuilt functionality provided by cloud providers like AWS, features can be delivered in a fraction of the usual time, allowing developers to focus on coding and feature development rather than infrastructure management. As serverless adoption continues to grow, major cloud providers such as AWS, Google, and Azure are expanding their serverless offerings to cater to the increasing number of companies embracing serverless in production. These providers aim to capture more business by enhancing their suite of serverless services, enabling developers to access advanced features and integrate pre-made services without manual infrastructure provisioning or complex setup.
By embracing serverless architecture and utilizing Sedai's autonomous capabilities, businesses can streamline operations, boost developer efficiency, and unlock the vast potential offered by the expanding suite of serverless services from cloud providers.