
Register now

96% of enterprises are now running Kubernetes. That sounds great, but the reality is most teams still overspend or overprovision. To protect uptime, engineers add safety buffers or oversize clusters, which cancel out the savings autoscaling was supposed to deliver.
The Cast AI benchmark highlights an 8x over-provisioning gap between requested and actual CPU usage. On average, CPU utilization across Kubernetes clusters is just 13%. The numbers are staggering, but they highlight a simple truth: reactive autoscaling leaves both budgets and performance exposed.
Over the years, we’ve worked with engineering teams caught in this cycle of runaway costs and reliability risks. This guide breaks down why traditional autoscaling often fails in practice, what mechanisms exist today, and how autonomous systems like Sedai resolve the trade-off between cost and performance.
Datadog’s survey of Kubernetes deployments reports average CPU usage at 20 to 30 percent and memory usage at 30 to 40 percent. That gap exists because teams have to make trade-offs. Without automation, the options are limited: either oversize clusters to protect uptime or undersize them to save money and risk degraded services. Neither approach is sustainable.
Autoscaling solves this resource-balancing problem by matching supply with demand. Kubernetes autoscaling is the automatic adjustment of workloads and cluster capacity based on metrics or external signals. This can mean increasing pod replicas when CPU utilization climbs, adjusting pod resource requests based on historical usage, or adding nodes to absorb unscheduled workloads.
What we’ve learned from years of working with engineering teams is that traditional autoscalers tend to focus narrowly on cost signals. Engineers compensate by overprovisioning or hard-coding safety buffers to keep performance intact. The result is a system that claims to optimize resources but often leaves both cost and availability unresolved.

Modern applications rarely run at a steady load. A retail platform may see order volumes spike during a flash sale, while a streaming service can experience a sudden surge when new content is released. Scaling clusters manually during every event is not realistic, which is why autoscaling is essential.
When it works as intended, autoscaling provides four key benefits:
The problem is that these benefits only appear when autoscaling is configured carefully. Misconfigured policies can cause constant oscillation between scaling up and down, sluggish reactions to traffic surges, or resource starvation that impacts end users.
In our experience, this is where engineering teams get stuck: the intent is to balance cost and performance, but traditional autoscalers force a trade-off that leaves one side exposed.
That’s why, as we go deeper into Kubernetes autoscaling mechanisms and strategies, we’ll focus on how to approach this balance in a way that reduces waste without sacrificing reliability.
Studies of Kubernetes clusters show a consistent inefficiency: only 20–45 % of the requested CPU and memory is actually consumed. Kubernetes autoscaling aims to close this gap, but in practice, it’s less about “set and forget” and more about knowing where each mechanism fits and where it can fail.
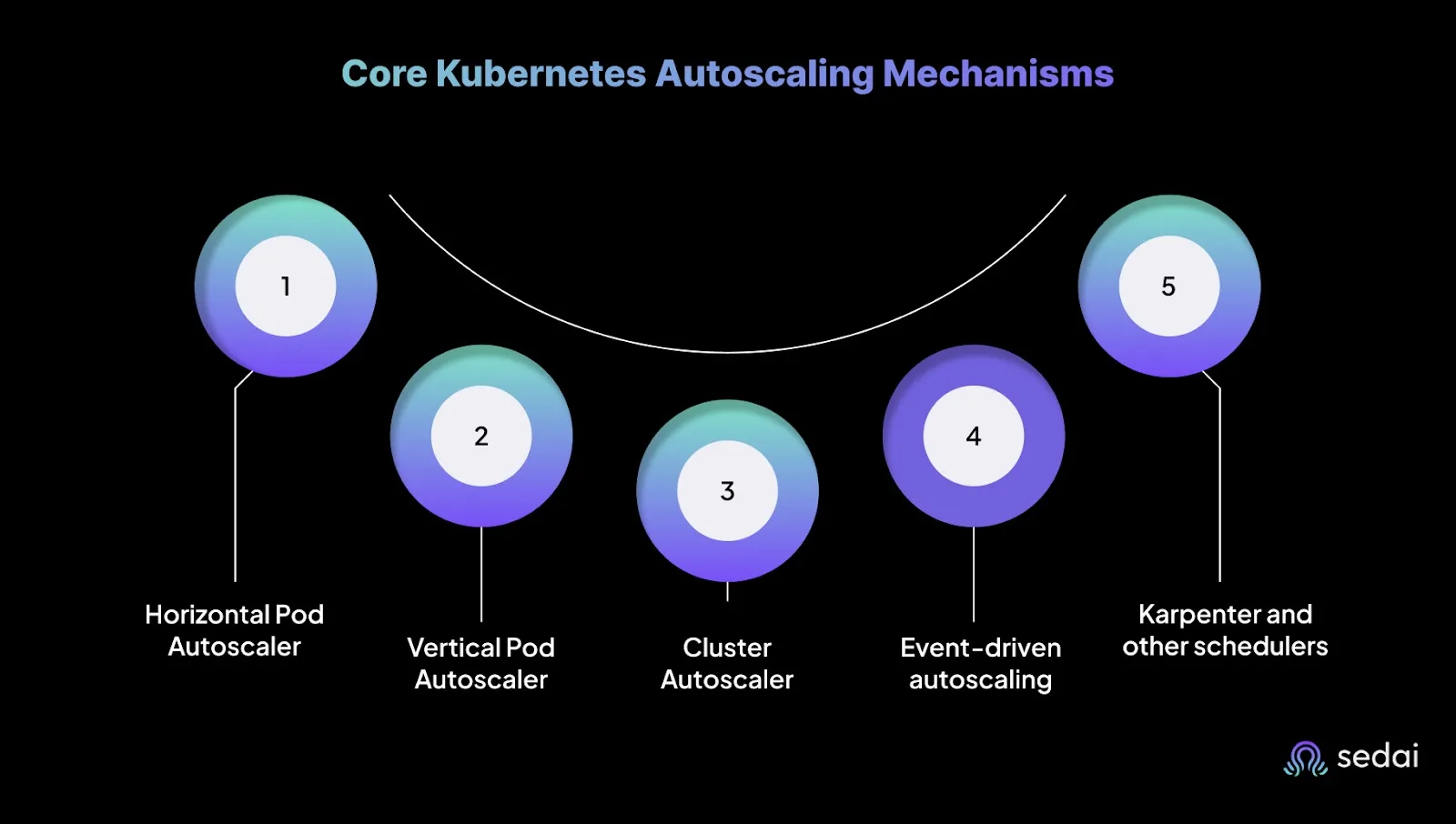
The main mechanisms are:
HPA adjusts the number of running pods within a deployment or stateful set. It operates as a control loop in the Kubernetes controller manager with a default interval of 15 seconds.
At each interval, it reads metrics (typically CPU or memory) from the metrics API or a custom metrics adapter, calculates the ratio of current value to target, and computes the desired number of pods.
If the ratio deviates beyond a tolerance (default 10 %), the HPA modifies the replica count. Key aspects:
VPA adjusts CPU and memory requests for individual pods. It monitors historic resource consumption, recommends new resource values, and can evict pods to apply updated requests. VPA is useful when applications need more memory or CPU than originally specified or when resources have been overestimated.
Considerations include:
The Cluster Autoscaler (CA) adjusts the number of nodes in a cluster. It observes unscheduled pods: if pods cannot be placed when no node has enough resources, the CA adds nodes to the cluster. If nodes remain underutilized for a sustained period and all their pods can be rescheduled elsewhere, CA removes the nodes. Important points:
Kubernetes Event‑Driven Autoscaling (KEDA) extends HPA to react to external event sources like Kafka queue lag, HTTP queue length, or Pub/Sub messages. It defines triggers that convert event counts into desired replica counts using formulas similar to the HPA. Tuning KEDA requires:
Karpenter is a newer node‑provisioning tool that aims to replace CA. It makes scheduling decisions per pod, launching the right size of node for each pending pod, and consolidating under‑utilized nodes. This reduces bin‑packing inefficiencies and speeds up scaling. In 2025, many managed services support Karpenter for dynamic clusters, and engineering teams adopt it for faster scale‑up and lower costs.
Each autoscaler solves a different problem, but none are perfect. HPA can oscillate, VPA introduces restarts, CA lags behind bursts, KEDA can overreact to noisy events, and Karpenter, while powerful, is still maturing. The trade-off isn’t whether to use autoscaling, but how to tune and combine these mechanisms without letting them quietly bleed money or disrupt stability.
What many engineering leaders point out is that these mechanisms are fundamentally reactive. They wait for CPU, memory, or event thresholds to be crossed before making adjustments.
That means scaling always lags behind demand, and engineers are left constantly tuning guardrails to minimize cost without risking downtime.
This gap is why autonomous scaling has become such a priority. It’s not about whether Kubernetes can scale, but about whether it can scale proactively, in real time, and without human tuning.
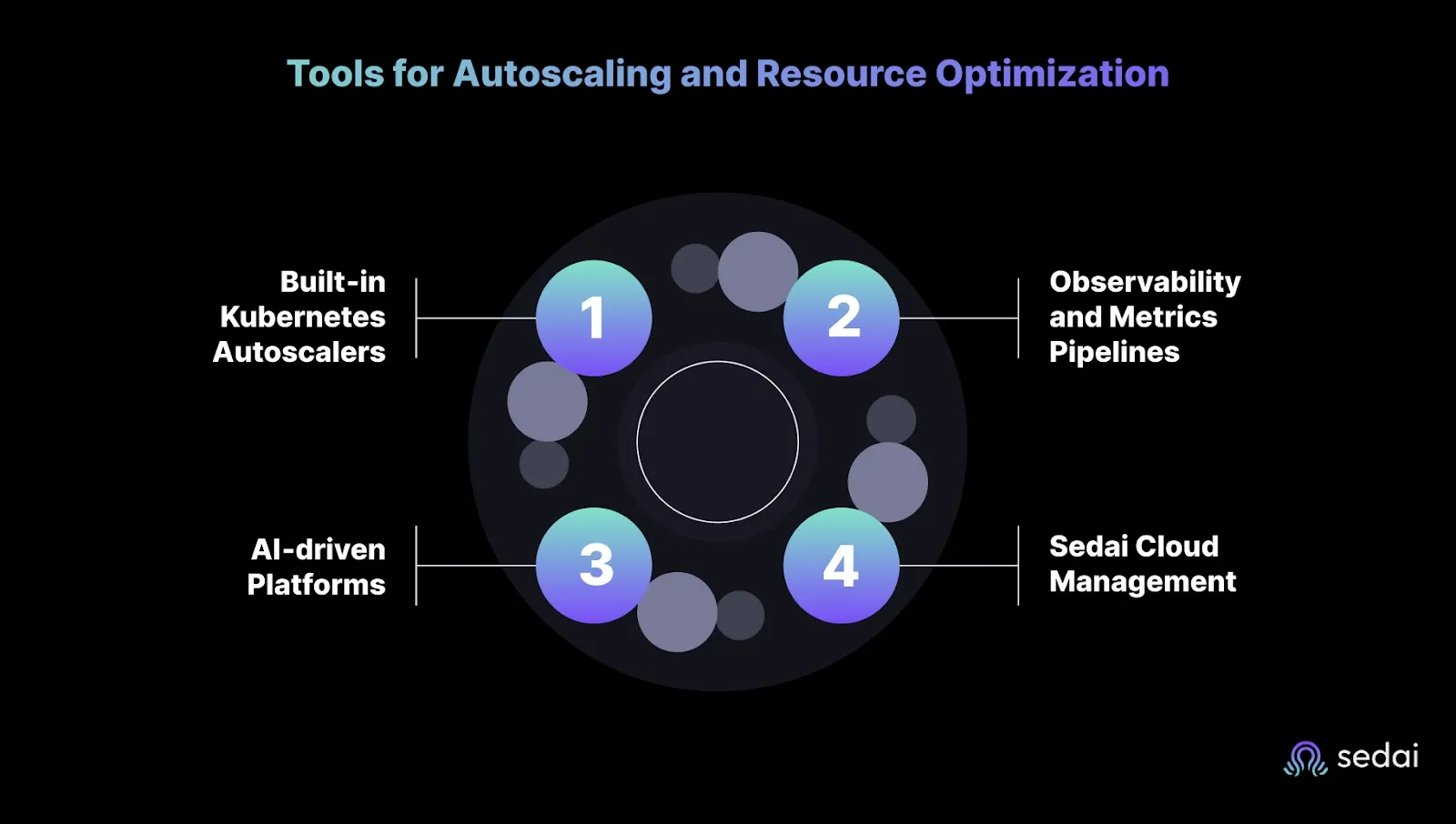
Kubernetes offers several ways to scale, but each comes with trade-offs. To succeed in production, engineering teams often combine built-in tools, observability pipelines, and newer AI-driven platforms. The real question is not what tools exist , but when they’re safe to rely on, and when they fall short.
HPA, VPA, and Cluster Autoscaler cover the basics and are widely available in managed services. They work well in environments with gradual, predictable changes in demand. But the moment traffic shifts rapidly, like during a flash sale or streaming premiere, these tools reveal their reactive nature. Scaling lags behind reality, which is why engineers keep padding requests or overprovisioning to avoid user-facing failures.
Metrics Server, Prometheus, and OpenTelemetry extend what autoscalers can see. They’re powerful for steady workloads where a slight reporting delay doesn’t matter. But in production surges, those delays often stretch to 15–30 seconds. That gap means scaling kicks in after the user experience has already degraded, forcing operators to compensate with permanent buffers that eat into efficiency.
AI-based tools improve on static thresholds by analyzing historical patterns and adjusting policies dynamically. They reduce manual tuning and can even predict demand. But they’re still reactive at the core, scaling only after utilization shifts or predicted thresholds are breached. This is safe when workloads have strong, repeatable patterns (e.g., daily traffic cycles). But risky when unpredictable bursts, where “predicted” demand is already out of date the moment traffic hits.
Where AI-driven platforms predict demand, autonomous systems take the next step by continuously learning normal application behavior and acting without human intervention.
Sedai’s autonomous system continuously learns an application’s normal behaviour and makes scaling decisions that prioritize both performance and availability.
Sedai’s AI monitors workload behaviour and traffic trends, and scales resources before spikes and rightsizes after demand subsides. The platform integrates pod‑level and node‑level scaling with anomaly detection, early warning, and chaos testing.
For engineering leaders, the value is not just about cutting costs but also about freeing teams from constant tuning while maintaining service reliability.
Public cloud spending on IaaS and PaaS is expected to hit $440 billion in 2025 (McKinsey). Yet engineering leaders consistently report that 30–50% of this spend goes to waste. Much of that waste stems from scaling strategies that optimize for cost alone, without factoring in reliability. And as many seasoned practitioners will tell you, cost savings that degrade availability aren’t savings at all.
The following best practices will help you optimize Kubernetes autoscaling for both efficiency and reliability.
You can't optimize what you haven’t measured accurately. One of the biggest mistakes we see engineering teams make is setting unrealistic resource requests. If you set your CPU and memory too high, the system might not scale as effectively as it should, leading to wasted resources. Even worse, if the requested resources are too low, you could face resource starvation and performance issues.
You need profiling tools and load tests to understand the actual resource demands for each container. Avoid the temptation of huge buffers (it’s easy to overcompensate). Cast AI’s benchmark found that developers often request far more CPU than needed, creating a 43% gap between provisioned and requested CPUs. Proper right-sizing can improve scaling decisions and reduce unnecessary costs.
Many teams default to CPU and memory metrics, but those can be misleading. An app under heavy request load might still show low CPU usage, and by the time it scales, it’s already lagging.
That’s why you need metrics tied directly to demand, such as request rate, queue depth, or response time for stateless workloads, and query rate or Kafka lag for stateful ones. These are closer to what end users actually experience.
The mechanics of autoscaling go beyond what you measure to when you act on it. A sync interval that’s too aggressive leads to thrashing, with pods spinning up and down so fast that resources and budgets get wasted. Too conservative, and your system lags behind real demand, exposing users to slowdowns.
Traditional Kubernetes tools leave this tuning to operators, which is why many teams end up overprovisioning to stay safe. The result: higher bills and more operational drag.
Cost optimization that comes at the expense of performance isn’t optimization at all. Sedai aims to solve this by dynamically adjusting thresholds in real time, so scaling aligns with actual behavior instead of static rules.
Predictive autoscaling uses machine learning to forecast demand based on historical patterns, scaling ahead of the need.
Event‑driven scaling via tools like KEDA allows autoscalers to react to external triggers such as message queues or streaming platforms, ensuring that resources are allocated efficiently in real-time without waiting for utilization metrics to catch up.
Running both HPA and VPA on the same deployment can yield conflicting actions: VPA modifies pod requests, which changes the denominator of the HPA utilization calculation. To use them together, configure HPA to scale on custom metrics, with VPA controlling CPU and memory requests. Another approach is to run them separately: use VPA for batch jobs and HPA for stateless web services.
By 2027, nearly 90% of organizations will be running a hybrid cloud. That sounds impressive on a slide, but the messy reality is dozens of clusters, spread across providers, each scaling differently.
Aligning autoscaling policies across clusters can prevent overprovisioning and ensure that resources are allocated efficiently.
Federation tools and multi-cluster controllers help coordinate scaling decisions across diverse environments, ensuring a streamlined autoscaling strategy that spans on-premises and cloud environments.
In many companies, autoscaling is often seen as a technical function rather than a financial one. But the truth is, autoscaling is as critical for your FinOps strategy.
McKinsey’s research shows that integrating cost principles into infrastructure management, FinOps as code, can unlock about $120 billion in value, a savings of 10–20 %. Embedding cost policies into code helps engineers see the budget impact when adjusting scaling thresholds.
Not every workload deserves the same type of compute. Batch jobs can happily run on cheap, interruptible spot instances, while always-on services are better on reserved capacity. The math is obvious, the execution is not.
Expecting engineers to manually juggle spot vs. reserved across thousands of workloads is wishful thinking. No one has time for that. Sedai helps automate these decisions, ensuring that resources are allocated dynamically and cost-effectively without compromising performance.
Cloud providers love it when you forget things. A stray volume here, an unused IP there, it all adds up to a steady drip of charges you barely notice until the bill hits. And the worst part? None of it delivers a single ounce of value.
Continuous cleanup should be non-negotiable. Automated detection tools or custom guardrails can help identify and remove unused resources on a continuous basis. Regular cleanup not only improves cost efficiency but also reduces operational clutter, often resulting in 30–50% savings on cloud spend.
Running environments around the clock when they’re not needed is avoidable waste. Non-production systems should be scheduled to shut down outside working hours. Tools like Karpenter and KEDA facilitate zero-replica deployments, where services automatically scale down to zero replicas during idle periods, spinning back up instantly when events occur.
Autoscaling policies aren’t set-and-forget. Traffic patterns shift, marketing pushes happen, and suddenly those carefully tuned thresholds from six months ago are burning money or throttling performance.
If you aren’t auditing scaling configs on a regular cadence, you’re basically betting your reliability and your budget on outdated assumptions.
Schedule reviews the same way you schedule code audits. Minimum and maximum replica counts, thresholds, budgets, everything needs a sanity check. Otherwise, you’ll find out the hard way when your app slows down or your bill explodes.
Engineering teams increasingly realize that reactive scaling is not enough. Workloads don’t follow predictable patterns, and waiting for utilization thresholds to trigger scaling often means you’re already behind.
That’s why a growing number of engineering teams are now using AI platforms like Sedai. An AI‑driven platform that learns each workload’s behaviour and makes proactive scaling decisions.
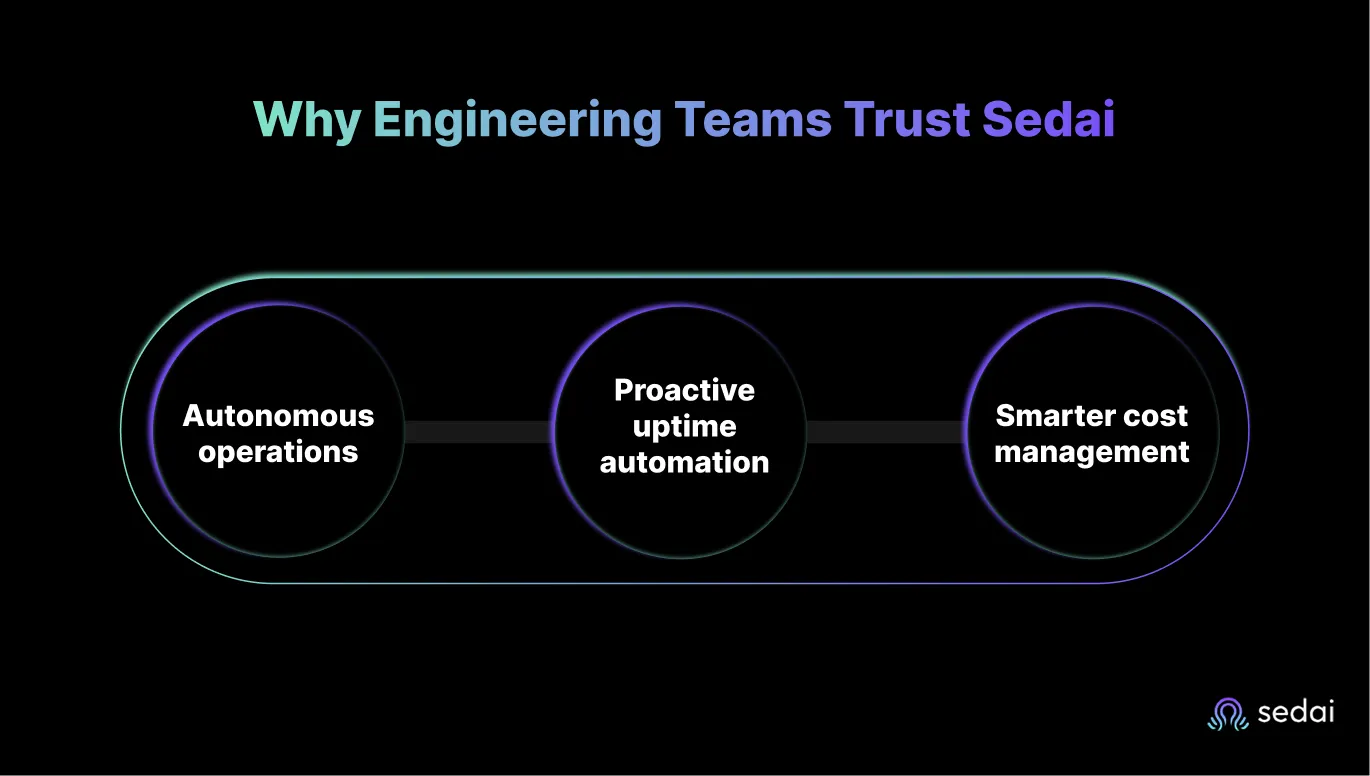
Engineering teams that trust Sedai’s autonomous cloud platform cite three core strengths:
Rather than simply adjusting pod counts based on CPU, Sedai’s platform acts as an intelligent operator that aligns scaling with business outcomes – performance, reliability, and cost.
Autoscaling is critical to running modern applications. Our experience in helping engineering teams tune autoscalers reveals that the traditional approaches (HPA, VPA, CA, KEDA, Karpenter) all share a common flaw: they are reactive. They wait for utilization to change, forcing engineers to compensate with buffers, overprovisioning, and endless tuning. The result is the same trade-off every time: reducing costs means risking downtime, while protecting uptime means wasting budget.
That cycle doesn’t break with more thresholds or “best practices.” It only breaks with autonomy. This is why engineering teams complement these tools with autonomous systems like Sedai. By integrating Sedai's automation tools, organizations can maximize the potential of autoscaling in Kubernetes, resulting in improved performance, enhanced scalability, and better cost management across their cloud environments.
Join us and gain full visibility and control over your Kubernetes environment.
Select metrics that correlate with user‑perceived load. CPU and memory are common, but may not represent demand for I/O‑bound or latency‑sensitive services. Consider metrics like request rate, error rate, or Kafka lag. Use custom metrics via Prometheus adapter or KEDA triggers.
Event‑driven scaling is ideal for microservices where work is queued, such as message processing or asynchronous tasks. For request‑driven web services, CPU or request rate metrics may be more appropriate. Combining event triggers with HPA gives fine‑grained control.
Traditional autoscalers use static thresholds and focus primarily on utilisation. Sedai’s autonomous system learns workload patterns, detects anomalies, orchestrates both pod and node scaling, and integrates FinOps policies. This holistic approach yields significant performance improvements and cost savings without manual tuning.
HPA modifies the number of pods to match observed metrics: VPA changes the CPU and memory requests for individual pods. HPA scales horizontally and keeps pods stateless, whereas VPA optimizes resource requests vertically. When using both, scale on custom metrics to avoid conflicting CPU/memory calculations.

September 9, 2025
September 12, 2025
96% of enterprises are now running Kubernetes. That sounds great, but the reality is most teams still overspend or overprovision. To protect uptime, engineers add safety buffers or oversize clusters, which cancel out the savings autoscaling was supposed to deliver.
The Cast AI benchmark highlights an 8x over-provisioning gap between requested and actual CPU usage. On average, CPU utilization across Kubernetes clusters is just 13%. The numbers are staggering, but they highlight a simple truth: reactive autoscaling leaves both budgets and performance exposed.
Over the years, we’ve worked with engineering teams caught in this cycle of runaway costs and reliability risks. This guide breaks down why traditional autoscaling often fails in practice, what mechanisms exist today, and how autonomous systems like Sedai resolve the trade-off between cost and performance.
Datadog’s survey of Kubernetes deployments reports average CPU usage at 20 to 30 percent and memory usage at 30 to 40 percent. That gap exists because teams have to make trade-offs. Without automation, the options are limited: either oversize clusters to protect uptime or undersize them to save money and risk degraded services. Neither approach is sustainable.
Autoscaling solves this resource-balancing problem by matching supply with demand. Kubernetes autoscaling is the automatic adjustment of workloads and cluster capacity based on metrics or external signals. This can mean increasing pod replicas when CPU utilization climbs, adjusting pod resource requests based on historical usage, or adding nodes to absorb unscheduled workloads.
What we’ve learned from years of working with engineering teams is that traditional autoscalers tend to focus narrowly on cost signals. Engineers compensate by overprovisioning or hard-coding safety buffers to keep performance intact. The result is a system that claims to optimize resources but often leaves both cost and availability unresolved.
Modern applications rarely run at a steady load. A retail platform may see order volumes spike during a flash sale, while a streaming service can experience a sudden surge when new content is released. Scaling clusters manually during every event is not realistic, which is why autoscaling is essential.
When it works as intended, autoscaling provides four key benefits:
The problem is that these benefits only appear when autoscaling is configured carefully. Misconfigured policies can cause constant oscillation between scaling up and down, sluggish reactions to traffic surges, or resource starvation that impacts end users.
In our experience, this is where engineering teams get stuck: the intent is to balance cost and performance, but traditional autoscalers force a trade-off that leaves one side exposed.
That’s why, as we go deeper into Kubernetes autoscaling mechanisms and strategies, we’ll focus on how to approach this balance in a way that reduces waste without sacrificing reliability.
Studies of Kubernetes clusters show a consistent inefficiency: only 20–45 % of the requested CPU and memory is actually consumed. Kubernetes autoscaling aims to close this gap, but in practice, it’s less about “set and forget” and more about knowing where each mechanism fits and where it can fail.
The main mechanisms are:
HPA adjusts the number of running pods within a deployment or stateful set. It operates as a control loop in the Kubernetes controller manager with a default interval of 15 seconds.
At each interval, it reads metrics (typically CPU or memory) from the metrics API or a custom metrics adapter, calculates the ratio of current value to target, and computes the desired number of pods.
If the ratio deviates beyond a tolerance (default 10 %), the HPA modifies the replica count. Key aspects:
VPA adjusts CPU and memory requests for individual pods. It monitors historic resource consumption, recommends new resource values, and can evict pods to apply updated requests. VPA is useful when applications need more memory or CPU than originally specified or when resources have been overestimated.
Considerations include:
The Cluster Autoscaler (CA) adjusts the number of nodes in a cluster. It observes unscheduled pods: if pods cannot be placed when no node has enough resources, the CA adds nodes to the cluster. If nodes remain underutilized for a sustained period and all their pods can be rescheduled elsewhere, CA removes the nodes. Important points:
Kubernetes Event‑Driven Autoscaling (KEDA) extends HPA to react to external event sources like Kafka queue lag, HTTP queue length, or Pub/Sub messages. It defines triggers that convert event counts into desired replica counts using formulas similar to the HPA. Tuning KEDA requires:
Karpenter is a newer node‑provisioning tool that aims to replace CA. It makes scheduling decisions per pod, launching the right size of node for each pending pod, and consolidating under‑utilized nodes. This reduces bin‑packing inefficiencies and speeds up scaling. In 2025, many managed services support Karpenter for dynamic clusters, and engineering teams adopt it for faster scale‑up and lower costs.
Each autoscaler solves a different problem, but none are perfect. HPA can oscillate, VPA introduces restarts, CA lags behind bursts, KEDA can overreact to noisy events, and Karpenter, while powerful, is still maturing. The trade-off isn’t whether to use autoscaling, but how to tune and combine these mechanisms without letting them quietly bleed money or disrupt stability.
What many engineering leaders point out is that these mechanisms are fundamentally reactive. They wait for CPU, memory, or event thresholds to be crossed before making adjustments.
That means scaling always lags behind demand, and engineers are left constantly tuning guardrails to minimize cost without risking downtime.
This gap is why autonomous scaling has become such a priority. It’s not about whether Kubernetes can scale, but about whether it can scale proactively, in real time, and without human tuning.
Kubernetes offers several ways to scale, but each comes with trade-offs. To succeed in production, engineering teams often combine built-in tools, observability pipelines, and newer AI-driven platforms. The real question is not what tools exist , but when they’re safe to rely on, and when they fall short.
HPA, VPA, and Cluster Autoscaler cover the basics and are widely available in managed services. They work well in environments with gradual, predictable changes in demand. But the moment traffic shifts rapidly, like during a flash sale or streaming premiere, these tools reveal their reactive nature. Scaling lags behind reality, which is why engineers keep padding requests or overprovisioning to avoid user-facing failures.
Metrics Server, Prometheus, and OpenTelemetry extend what autoscalers can see. They’re powerful for steady workloads where a slight reporting delay doesn’t matter. But in production surges, those delays often stretch to 15–30 seconds. That gap means scaling kicks in after the user experience has already degraded, forcing operators to compensate with permanent buffers that eat into efficiency.
AI-based tools improve on static thresholds by analyzing historical patterns and adjusting policies dynamically. They reduce manual tuning and can even predict demand. But they’re still reactive at the core, scaling only after utilization shifts or predicted thresholds are breached. This is safe when workloads have strong, repeatable patterns (e.g., daily traffic cycles). But risky when unpredictable bursts, where “predicted” demand is already out of date the moment traffic hits.
Where AI-driven platforms predict demand, autonomous systems take the next step by continuously learning normal application behavior and acting without human intervention.
Sedai’s autonomous system continuously learns an application’s normal behaviour and makes scaling decisions that prioritize both performance and availability.
Sedai’s AI monitors workload behaviour and traffic trends, and scales resources before spikes and rightsizes after demand subsides. The platform integrates pod‑level and node‑level scaling with anomaly detection, early warning, and chaos testing.
For engineering leaders, the value is not just about cutting costs but also about freeing teams from constant tuning while maintaining service reliability.
Public cloud spending on IaaS and PaaS is expected to hit $440 billion in 2025 (McKinsey). Yet engineering leaders consistently report that 30–50% of this spend goes to waste. Much of that waste stems from scaling strategies that optimize for cost alone, without factoring in reliability. And as many seasoned practitioners will tell you, cost savings that degrade availability aren’t savings at all.
The following best practices will help you optimize Kubernetes autoscaling for both efficiency and reliability.
You can't optimize what you haven’t measured accurately. One of the biggest mistakes we see engineering teams make is setting unrealistic resource requests. If you set your CPU and memory too high, the system might not scale as effectively as it should, leading to wasted resources. Even worse, if the requested resources are too low, you could face resource starvation and performance issues.
You need profiling tools and load tests to understand the actual resource demands for each container. Avoid the temptation of huge buffers (it’s easy to overcompensate). Cast AI’s benchmark found that developers often request far more CPU than needed, creating a 43% gap between provisioned and requested CPUs. Proper right-sizing can improve scaling decisions and reduce unnecessary costs.
Many teams default to CPU and memory metrics, but those can be misleading. An app under heavy request load might still show low CPU usage, and by the time it scales, it’s already lagging.
That’s why you need metrics tied directly to demand, such as request rate, queue depth, or response time for stateless workloads, and query rate or Kafka lag for stateful ones. These are closer to what end users actually experience.
The mechanics of autoscaling go beyond what you measure to when you act on it. A sync interval that’s too aggressive leads to thrashing, with pods spinning up and down so fast that resources and budgets get wasted. Too conservative, and your system lags behind real demand, exposing users to slowdowns.
Traditional Kubernetes tools leave this tuning to operators, which is why many teams end up overprovisioning to stay safe. The result: higher bills and more operational drag.
Cost optimization that comes at the expense of performance isn’t optimization at all. Sedai aims to solve this by dynamically adjusting thresholds in real time, so scaling aligns with actual behavior instead of static rules.
Predictive autoscaling uses machine learning to forecast demand based on historical patterns, scaling ahead of the need.
Event‑driven scaling via tools like KEDA allows autoscalers to react to external triggers such as message queues or streaming platforms, ensuring that resources are allocated efficiently in real-time without waiting for utilization metrics to catch up.
Running both HPA and VPA on the same deployment can yield conflicting actions: VPA modifies pod requests, which changes the denominator of the HPA utilization calculation. To use them together, configure HPA to scale on custom metrics, with VPA controlling CPU and memory requests. Another approach is to run them separately: use VPA for batch jobs and HPA for stateless web services.
By 2027, nearly 90% of organizations will be running a hybrid cloud. That sounds impressive on a slide, but the messy reality is dozens of clusters, spread across providers, each scaling differently.
Aligning autoscaling policies across clusters can prevent overprovisioning and ensure that resources are allocated efficiently.
Federation tools and multi-cluster controllers help coordinate scaling decisions across diverse environments, ensuring a streamlined autoscaling strategy that spans on-premises and cloud environments.
In many companies, autoscaling is often seen as a technical function rather than a financial one. But the truth is, autoscaling is as critical for your FinOps strategy.
McKinsey’s research shows that integrating cost principles into infrastructure management, FinOps as code, can unlock about $120 billion in value, a savings of 10–20 %. Embedding cost policies into code helps engineers see the budget impact when adjusting scaling thresholds.
Not every workload deserves the same type of compute. Batch jobs can happily run on cheap, interruptible spot instances, while always-on services are better on reserved capacity. The math is obvious, the execution is not.
Expecting engineers to manually juggle spot vs. reserved across thousands of workloads is wishful thinking. No one has time for that. Sedai helps automate these decisions, ensuring that resources are allocated dynamically and cost-effectively without compromising performance.
Cloud providers love it when you forget things. A stray volume here, an unused IP there, it all adds up to a steady drip of charges you barely notice until the bill hits. And the worst part? None of it delivers a single ounce of value.
Continuous cleanup should be non-negotiable. Automated detection tools or custom guardrails can help identify and remove unused resources on a continuous basis. Regular cleanup not only improves cost efficiency but also reduces operational clutter, often resulting in 30–50% savings on cloud spend.
Running environments around the clock when they’re not needed is avoidable waste. Non-production systems should be scheduled to shut down outside working hours. Tools like Karpenter and KEDA facilitate zero-replica deployments, where services automatically scale down to zero replicas during idle periods, spinning back up instantly when events occur.
Autoscaling policies aren’t set-and-forget. Traffic patterns shift, marketing pushes happen, and suddenly those carefully tuned thresholds from six months ago are burning money or throttling performance.
If you aren’t auditing scaling configs on a regular cadence, you’re basically betting your reliability and your budget on outdated assumptions.
Schedule reviews the same way you schedule code audits. Minimum and maximum replica counts, thresholds, budgets, everything needs a sanity check. Otherwise, you’ll find out the hard way when your app slows down or your bill explodes.
Engineering teams increasingly realize that reactive scaling is not enough. Workloads don’t follow predictable patterns, and waiting for utilization thresholds to trigger scaling often means you’re already behind.
That’s why a growing number of engineering teams are now using AI platforms like Sedai. An AI‑driven platform that learns each workload’s behaviour and makes proactive scaling decisions.
Engineering teams that trust Sedai’s autonomous cloud platform cite three core strengths:
Rather than simply adjusting pod counts based on CPU, Sedai’s platform acts as an intelligent operator that aligns scaling with business outcomes – performance, reliability, and cost.
Autoscaling is critical to running modern applications. Our experience in helping engineering teams tune autoscalers reveals that the traditional approaches (HPA, VPA, CA, KEDA, Karpenter) all share a common flaw: they are reactive. They wait for utilization to change, forcing engineers to compensate with buffers, overprovisioning, and endless tuning. The result is the same trade-off every time: reducing costs means risking downtime, while protecting uptime means wasting budget.
That cycle doesn’t break with more thresholds or “best practices.” It only breaks with autonomy. This is why engineering teams complement these tools with autonomous systems like Sedai. By integrating Sedai's automation tools, organizations can maximize the potential of autoscaling in Kubernetes, resulting in improved performance, enhanced scalability, and better cost management across their cloud environments.
Join us and gain full visibility and control over your Kubernetes environment.
Select metrics that correlate with user‑perceived load. CPU and memory are common, but may not represent demand for I/O‑bound or latency‑sensitive services. Consider metrics like request rate, error rate, or Kafka lag. Use custom metrics via Prometheus adapter or KEDA triggers.
Event‑driven scaling is ideal for microservices where work is queued, such as message processing or asynchronous tasks. For request‑driven web services, CPU or request rate metrics may be more appropriate. Combining event triggers with HPA gives fine‑grained control.
Traditional autoscalers use static thresholds and focus primarily on utilisation. Sedai’s autonomous system learns workload patterns, detects anomalies, orchestrates both pod and node scaling, and integrates FinOps policies. This holistic approach yields significant performance improvements and cost savings without manual tuning.
HPA modifies the number of pods to match observed metrics: VPA changes the CPU and memory requests for individual pods. HPA scales horizontally and keeps pods stateless, whereas VPA optimizes resource requests vertically. When using both, scale on custom metrics to avoid conflicting CPU/memory calculations.






.svg)
.svg)




%201.svg)
%202.svg)

.svg)



