

Register now


September 10, 2025
September 3, 2025
September 10, 2025
September 3, 2025
Your cloud is getting more complex every quarter, but your team’s ability to keep up isn’t growing at the same pace. It's no wonder that 85% of enterprises are relying on cloud automation to handle repetitive work and keep systems running. Yet despite this wide adoption, conventional, rule-based automation often makes life harder, not easier.
This is because the modern enterprise cloud changes constantly. Traffic spikes, new releases, and configuration shifts can break scripts that looked perfect yesterday. That’s why autonomous cloud management is emerging as the safer approach. Unlike static automation, autonomous systems learn how your unique environment behaves, adjusting in real time.
Before we explore autonomous cloud management in detail, it’s important to understand what cloud automation actually is, how it works, and why teams still rely on it as the foundation for reliable operations.
Cloud automation handles repetitive tasks: provisioning servers, configuring environments, scaling applications, and patching systems. Rules execute consistently across public, private, or hybrid clouds.
Cloud automation only works in predictable conditions. Instance constraints, network misconfigurations, or dependency conflicts can silently break scripts. In one environment, a misconfigured Terraform module repeatedly failed, requiring manual intervention. These issues are common in multi-team or hybrid-cloud setups.
Integration is crucial. Automation interacts with Terraform, Pulumi, Ansible, and Kubernetes operators. Misaligned states often cause failures. Alerts help, but static rules cannot handle unexpected conditions, and multi-region or cross-cloud failovers frequently exceed their scope.
From our experience across dozens of enterprise environments on AWS, Azure, and hybrid clouds, automation reduces grunt work but has limits. Knowing these boundaries helps you anticipate failures, integrate safely with existing tooling, and complement automation with systems that observe, learn, and act dynamically.
Once you understand where automation can struggle, the next question is how it fits into the bigger picture of cloud operations. Many teams confuse automation with orchestration, assuming they solve the same problems, but they don’t. Understanding the difference helps you set the right expectations and avoid unnecessary headaches.

Even with its limits, cloud automation remains appealing because it addresses the most repetitive and error-prone tasks in your environment. We see four areas where cloud automation adds value:
Automated workflows cut manual task time by up to 60%. You can roll out new features without provisioning every server by hand, scale resources during traffic spikes automatically, and reduce low-level errors. However, rules can misfire when conditions shift unexpectedly. For example, a dependency mismatch during a CI/CD pipeline rollback may cause scripts to fail silently, forcing manual intervention.
Even basic cloud automation improves resource efficiency. Rightsizing instances, shutting down idle systems, and applying consistent usage rules reduce infrastructure spend. From our work with over a dozen enterprise environments, we’ve seen teams cut up to 30% of spending using automation alone.
Beyond immediate savings, this also impacts the total cost of ownership by reducing ongoing operational toil, minimizing human error, and lowering the overhead of managing multiple clouds and tooling before even considering advanced autonomous strategies.
Manual configuration errors are common and costly. Cloud automation ensures that servers, networks, and deployments follow the same rules. Security checks, access controls, and auditing are executed reliably, which is critical for regulatory compliance. Misconfigurations here, even minor ones, can lead to outages or audit failures.
Scheduling backups and maintaining snapshots through cloud automation reduces the risk of data loss. Still, static rules cannot anticipate all failure conditions. We have seen backups fail during network congestion or region failovers, requiring manual intervention to restore continuity.
Note: Cloud automation has clear limits. Multi-cloud, hybrid deployments, and dynamic traffic create edge cases where scripts fail silently. The safest path is incremental adoption of autonomous systems: observe critical workflows alongside existing automation, validate in staging, then gradually shift production workloads. This approach lets autonomy handle routine operations, minimizes operational risk, and ensures ROI without disrupting current systems.
Before we dive into autonomy in more detail, there are a few practical questions about automation we still need to answer. How do you make it work effectively in your environment? Understanding this is key to deploying, securing, and scaling reliably while reducing manual toil.
If you want automation to actually deliver, it’s not enough to string together scripts and hope for the best. From our experience across multiple enterprise environments, successful teams treat automation as a structured system, not a collection of ad-hoc scripts. Here’s how the pieces fit together and what to watch for:
Defining servers, networks, and storage in code ensures environments are consistent and repeatable. We’ve seen failures when Terraform modules weren’t versioned correctly or when variable overrides caused subtle configuration drift, which often surfaces only during production deploys.
Integrating with Ansible or Kubernetes operators requires strict state management and validation pipelines. Without these safeguards, multi-region deployments or hybrid environments can silently fail, creating downtime and troubleshooting overhead.
Automating CI/CD pipelines reduces human error, but engineers need to account for failure patterns. Rollback scripts can fail if dependencies between microservices are misaligned or if external APIs behave unexpectedly. In one scenario, a staging environment that didn’t mirror production network constraints caused silent pipeline failures during a feature rollout. Mitigation requires parallel validation pipelines, automated health checks, and stepwise promotion to production to prevent disruptions.
Policy enforcement, access control, and compliance checks must happen consistently to prevent costly mistakes. Improperly automated IAM updates can lock out services or leave security gaps. We integrate security checks directly into deployment pipelines using policy-as-code, ensuring compliance is enforced continuously rather than retroactively. This approach also reduces the operational burden on engineers who would otherwise audit and fix security gaps manually.
Service catalogs and self-service portals allow engineers to provision resources independently while staying within guardrails. Static rules can fail under unusual traffic spikes, multi-cloud deployments, or hybrid workloads. By combining these portals with automated monitoring hooks, teams catch violations in real time and avoid the silent failures that plague traditional rule-based systems.

Even with structured building blocks in place, engineers often ask: where does automation actually make a measurable difference? From our experience automation is most impactful in three areas, each with clear boundaries and failure patterns that must be managed carefully.
Automating server, network, and storage provisioning through Infrastructure as Code reduces manual errors and deployment time. However, edge cases like transient API failures, region-specific resource limits, or misaligned environment variables can still break deployments. Teams we’ve worked with mitigate these risks by combining automated validation checks with staged rollouts, gradually promoting new environments from dev to production.
Automation in CI/CD accelerates feature delivery and ensures consistency. Rollback scripts, however, can silently fail under unusual conditions, such as unexpected API rate limits, service dependency conflicts, or network latency differences between staging and production. The most reliable teams implement parallel validation pipelines, automated health checks, and stepwise promotion strategies to catch issues early.
Running workloads across AWS, Azure, and private clouds introduces operational complexity. Automation ensures consistent policies for scaling, patching, and monitoring, but static rules struggle under sudden traffic spikes or cross-cloud dependencies. Observability hooks and real-time alerts help teams maintain control until autonomous systems can take over dynamic adjustments.
Cloud automation gets you part of the way, but it cannot react to every unexpected change in your cloud. That’s why we will show how autonomous systems learn from your environment and make adjustments in real time, handling situations that would normally require constant human attention.
You now know where traditional automation falls short. Even well-structured workflows struggle with unpredictable traffic spikes, multi-cloud dependencies, or unusual failure conditions. Autonomous cloud management fills that gap by continuously observing your environment, learning patterns, and adjusting resources and configurations in real time.
We’ve seen how autonomy addresses challenges engineers face every day:
By looking at cloud management this way, it’s clear that autonomy isn’t just a nice-to-have, but it’s the only way to operate safely and efficiently.
So, how do teams put autonomous cloud management into practice in complex environments?
Understanding the theory behind autonomy is one thing. Making it work safely in a production environment alongside your existing automation is another. From our experience across multiple enterprise clouds, a structured, incremental approach prevents disruption while delivering measurable impact.
We always start by running autonomous controls in parallel with existing automation. This shadow mode lets us collect data on workload patterns, traffic spikes, and failure scenarios without touching production behavior. In one environment, we discovered that a Kubernetes operator misconfiguration would silently throttle microservices during peak traffic. Observing first allowed us to adjust safety rules before the autonomous system ever touched production.
We never flip a switch for all workloads at once. Instead, we migrate one workflow at a time, starting with non-critical systems. As confidence grows, we expand to critical workloads. This stepwise promotion ensures that even unusual failure conditions like transient API errors or unexpected dependency conflicts are handled safely.
Autonomous systems must respect the declarative rules defined in Terraform, Ansible, and Kubernetes operators. In practice, we’ve seen teams break production environments when autonomy overwrites provisioning rules unintentionally. By integrating at the state level and enforcing validations, autonomous actions complement existing scripts rather than competing with them.
Real environments always present surprises. Traffic surges, region failovers, API rate limits, or hybrid-cloud interactions can trigger failure patterns that automation alone cannot catch. We replicate these scenarios in staging, validate autonomous responses, and adjust policies accordingly. This reduces risk and builds trust in the system.
From day one, we measure cost savings, latency improvements, and reduced operational toil. In one enterprise, we observed that implementing autonomy significantly removed low-level manual interventions, while freeing engineers to focus on higher-value initiatives.
Autonomy is powerful, but it’s not omnipotent. Multi-region outages, provider API downtime, or highly complex hybrid orchestrations still require human oversight. We explicitly define these boundaries and create clear intervention points so engineers know when to step in.
Finally, autonomy improves over time. The system continuously learns from workload behavior, but we treat it as a feedback loop rather than a set-and-forget solution. Regular reviews, policy updates, and metric analysis ensure that autonomous actions evolve alongside business needs and environmental changes.
Let’s look at how a real system adapts, learns, and keeps operations running smoothly.
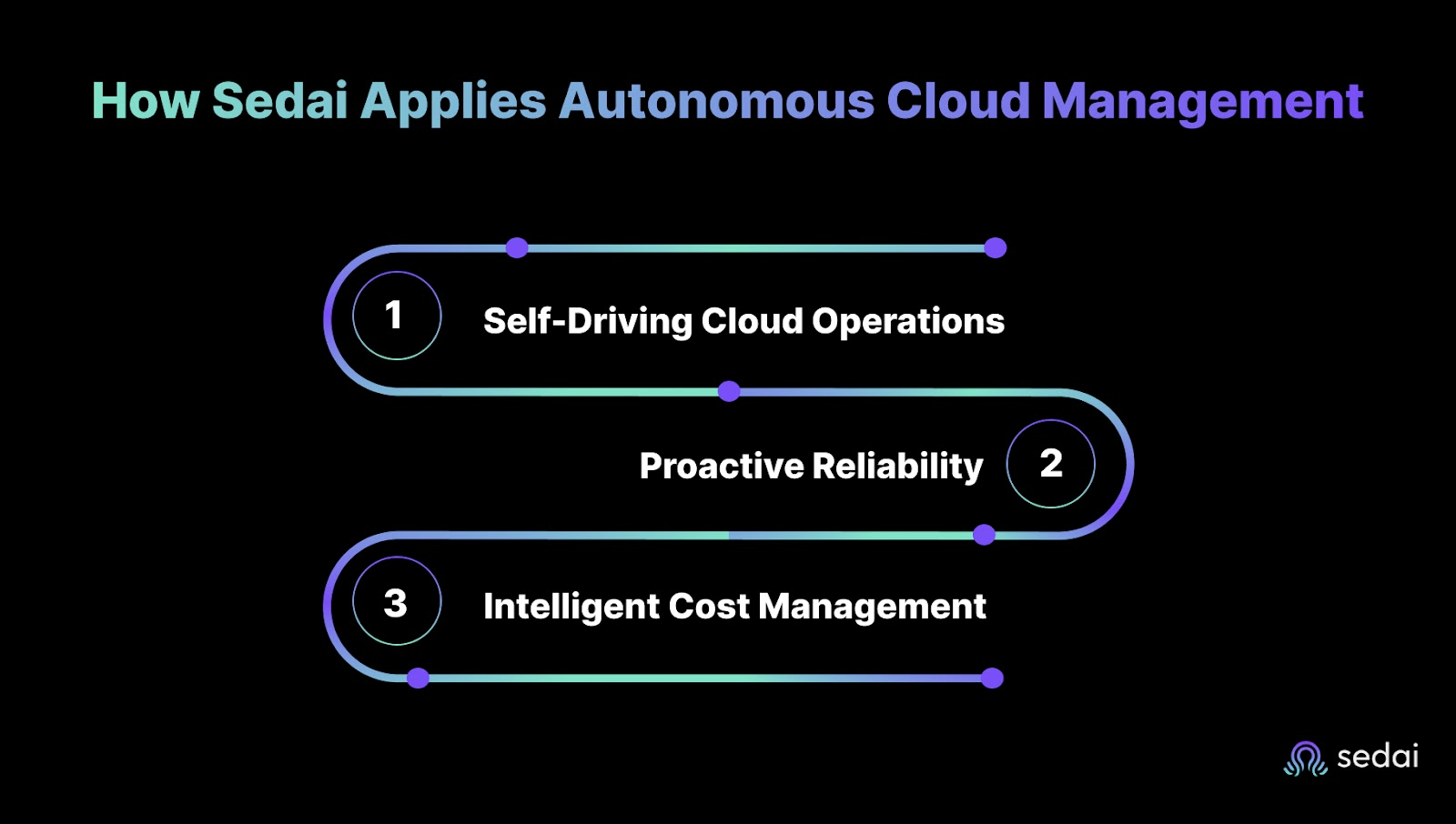
After struggling with scaling rules and deployment scripts long enough, it becomes clear that your team needs a system that complements human decision-making. Sedai observes, predicts, and adjusts workloads in real time, reducing manual toil while leaving engineers in control of critical decisions.
Sedai monitors workloads, scales applications, and adjusts configurations automatically. During traffic spikes or unexpected workload shifts, it reallocates compute resources to maintain performance. Companies have seen latency improvements of 30% to 75%, showing that adaptive systems handle conditions static scripts cannot.
Sedai detects early warning signs such as abnormal memory usage or unusual behaviors and remediates issues before they affect users. This preemptive handling can reduce failed customer interactions by up to 50% and improve overall system performance. Engineers familiar with traditional automation know how much time can be lost when something goes wrong: autonomy removes much of that repetitive troubleshooting.
By analyzing usage patterns and predicting resource demand, Sedai optimizes allocations and reduces wasted spend. Organizations using these strategies have reported 30% to 50% reductions in cloud costs without compromising performance or stability.
During the pandemic, Palo Alto Networks experienced a 5x growth in business and cloud workloads, creating significant operational complexity. Their SRE team managed thousands of workloads, including Kubernetes clusters and serverless environments, facing rising costs and increasing toil from manual management and static automation.
Sedai was integrated to optimize serverless and Kubernetes clusters across production and development environments. Its agents autonomously executed over 89,000 production changes with zero incidents.
The impact reported by the engineers included:
This example demonstrates how autonomous cloud management can operate reliably at scale, handling complexity that static automation cannot.
We’ve seen how rigid, rule-based automation struggles when conditions shift. Here’s the thing: autonomy, not automation alone, is the only way to manage a modern cloud safely at scale.
Moving forward, teams that adopt autonomy thoughtfully, starting with critical workflows, validating outcomes in staging, and scaling incrementally, can improve reliability, control costs, and focus engineering effort on higher-value projects. Organizations that embrace these approaches will be better positioned to handle unexpected workload spikes, hybrid and multi-cloud complexity, and rapid business growth.
If that’s the direction you want to explore, join us.
Traditional cloud automation follows static rules, while autonomous cloud management adapts in real time. It monitors changing traffic, system behavior, and deployments, making context-aware adjustments without waiting for human input.
Not reliably. Automation can handle predictable tasks, but as workloads span multiple providers or unexpected conditions arise, rule-based systems can fail. Autonomous management adds the adaptability cloud teams need for consistent performance.
By continuously analyzing workloads and predicting future resource needs, autonomous systems optimize allocation dynamically. This reduces wasted spend and ensures you’re only paying for what your cloud workloads truly require.
No. Cloud automation and autonomous platforms handle repetitive operational tasks, letting your engineers focus on higher-impact projects. It’s about augmenting your team, not replacing them.
Absolutely. Automation lays the foundation by executing predictable tasks reliably. Autonomy builds on that foundation, adapting to changes in real time, preventing failures, and improving efficiency across your cloud operations.
September 3, 2025
September 10, 2025
Your cloud is getting more complex every quarter, but your team’s ability to keep up isn’t growing at the same pace. It's no wonder that 85% of enterprises are relying on cloud automation to handle repetitive work and keep systems running. Yet despite this wide adoption, conventional, rule-based automation often makes life harder, not easier.
This is because the modern enterprise cloud changes constantly. Traffic spikes, new releases, and configuration shifts can break scripts that looked perfect yesterday. That’s why autonomous cloud management is emerging as the safer approach. Unlike static automation, autonomous systems learn how your unique environment behaves, adjusting in real time.
Before we explore autonomous cloud management in detail, it’s important to understand what cloud automation actually is, how it works, and why teams still rely on it as the foundation for reliable operations.
Cloud automation handles repetitive tasks: provisioning servers, configuring environments, scaling applications, and patching systems. Rules execute consistently across public, private, or hybrid clouds.
Cloud automation only works in predictable conditions. Instance constraints, network misconfigurations, or dependency conflicts can silently break scripts. In one environment, a misconfigured Terraform module repeatedly failed, requiring manual intervention. These issues are common in multi-team or hybrid-cloud setups.
Integration is crucial. Automation interacts with Terraform, Pulumi, Ansible, and Kubernetes operators. Misaligned states often cause failures. Alerts help, but static rules cannot handle unexpected conditions, and multi-region or cross-cloud failovers frequently exceed their scope.
From our experience across dozens of enterprise environments on AWS, Azure, and hybrid clouds, automation reduces grunt work but has limits. Knowing these boundaries helps you anticipate failures, integrate safely with existing tooling, and complement automation with systems that observe, learn, and act dynamically.
Once you understand where automation can struggle, the next question is how it fits into the bigger picture of cloud operations. Many teams confuse automation with orchestration, assuming they solve the same problems, but they don’t. Understanding the difference helps you set the right expectations and avoid unnecessary headaches.
Even with its limits, cloud automation remains appealing because it addresses the most repetitive and error-prone tasks in your environment. We see four areas where cloud automation adds value:
Automated workflows cut manual task time by up to 60%. You can roll out new features without provisioning every server by hand, scale resources during traffic spikes automatically, and reduce low-level errors. However, rules can misfire when conditions shift unexpectedly. For example, a dependency mismatch during a CI/CD pipeline rollback may cause scripts to fail silently, forcing manual intervention.
Even basic cloud automation improves resource efficiency. Rightsizing instances, shutting down idle systems, and applying consistent usage rules reduce infrastructure spend. From our work with over a dozen enterprise environments, we’ve seen teams cut up to 30% of spending using automation alone.
Beyond immediate savings, this also impacts the total cost of ownership by reducing ongoing operational toil, minimizing human error, and lowering the overhead of managing multiple clouds and tooling before even considering advanced autonomous strategies.
Manual configuration errors are common and costly. Cloud automation ensures that servers, networks, and deployments follow the same rules. Security checks, access controls, and auditing are executed reliably, which is critical for regulatory compliance. Misconfigurations here, even minor ones, can lead to outages or audit failures.
Scheduling backups and maintaining snapshots through cloud automation reduces the risk of data loss. Still, static rules cannot anticipate all failure conditions. We have seen backups fail during network congestion or region failovers, requiring manual intervention to restore continuity.
Note: Cloud automation has clear limits. Multi-cloud, hybrid deployments, and dynamic traffic create edge cases where scripts fail silently. The safest path is incremental adoption of autonomous systems: observe critical workflows alongside existing automation, validate in staging, then gradually shift production workloads. This approach lets autonomy handle routine operations, minimizes operational risk, and ensures ROI without disrupting current systems.
Before we dive into autonomy in more detail, there are a few practical questions about automation we still need to answer. How do you make it work effectively in your environment? Understanding this is key to deploying, securing, and scaling reliably while reducing manual toil.
If you want automation to actually deliver, it’s not enough to string together scripts and hope for the best. From our experience across multiple enterprise environments, successful teams treat automation as a structured system, not a collection of ad-hoc scripts. Here’s how the pieces fit together and what to watch for:
Defining servers, networks, and storage in code ensures environments are consistent and repeatable. We’ve seen failures when Terraform modules weren’t versioned correctly or when variable overrides caused subtle configuration drift, which often surfaces only during production deploys.
Integrating with Ansible or Kubernetes operators requires strict state management and validation pipelines. Without these safeguards, multi-region deployments or hybrid environments can silently fail, creating downtime and troubleshooting overhead.
Automating CI/CD pipelines reduces human error, but engineers need to account for failure patterns. Rollback scripts can fail if dependencies between microservices are misaligned or if external APIs behave unexpectedly. In one scenario, a staging environment that didn’t mirror production network constraints caused silent pipeline failures during a feature rollout. Mitigation requires parallel validation pipelines, automated health checks, and stepwise promotion to production to prevent disruptions.
Policy enforcement, access control, and compliance checks must happen consistently to prevent costly mistakes. Improperly automated IAM updates can lock out services or leave security gaps. We integrate security checks directly into deployment pipelines using policy-as-code, ensuring compliance is enforced continuously rather than retroactively. This approach also reduces the operational burden on engineers who would otherwise audit and fix security gaps manually.
Service catalogs and self-service portals allow engineers to provision resources independently while staying within guardrails. Static rules can fail under unusual traffic spikes, multi-cloud deployments, or hybrid workloads. By combining these portals with automated monitoring hooks, teams catch violations in real time and avoid the silent failures that plague traditional rule-based systems.
Even with structured building blocks in place, engineers often ask: where does automation actually make a measurable difference? From our experience automation is most impactful in three areas, each with clear boundaries and failure patterns that must be managed carefully.
Automating server, network, and storage provisioning through Infrastructure as Code reduces manual errors and deployment time. However, edge cases like transient API failures, region-specific resource limits, or misaligned environment variables can still break deployments. Teams we’ve worked with mitigate these risks by combining automated validation checks with staged rollouts, gradually promoting new environments from dev to production.
Automation in CI/CD accelerates feature delivery and ensures consistency. Rollback scripts, however, can silently fail under unusual conditions, such as unexpected API rate limits, service dependency conflicts, or network latency differences between staging and production. The most reliable teams implement parallel validation pipelines, automated health checks, and stepwise promotion strategies to catch issues early.
Running workloads across AWS, Azure, and private clouds introduces operational complexity. Automation ensures consistent policies for scaling, patching, and monitoring, but static rules struggle under sudden traffic spikes or cross-cloud dependencies. Observability hooks and real-time alerts help teams maintain control until autonomous systems can take over dynamic adjustments.
Cloud automation gets you part of the way, but it cannot react to every unexpected change in your cloud. That’s why we will show how autonomous systems learn from your environment and make adjustments in real time, handling situations that would normally require constant human attention.
You now know where traditional automation falls short. Even well-structured workflows struggle with unpredictable traffic spikes, multi-cloud dependencies, or unusual failure conditions. Autonomous cloud management fills that gap by continuously observing your environment, learning patterns, and adjusting resources and configurations in real time.
We’ve seen how autonomy addresses challenges engineers face every day:
By looking at cloud management this way, it’s clear that autonomy isn’t just a nice-to-have, but it’s the only way to operate safely and efficiently.
So, how do teams put autonomous cloud management into practice in complex environments?
Understanding the theory behind autonomy is one thing. Making it work safely in a production environment alongside your existing automation is another. From our experience across multiple enterprise clouds, a structured, incremental approach prevents disruption while delivering measurable impact.
We always start by running autonomous controls in parallel with existing automation. This shadow mode lets us collect data on workload patterns, traffic spikes, and failure scenarios without touching production behavior. In one environment, we discovered that a Kubernetes operator misconfiguration would silently throttle microservices during peak traffic. Observing first allowed us to adjust safety rules before the autonomous system ever touched production.
We never flip a switch for all workloads at once. Instead, we migrate one workflow at a time, starting with non-critical systems. As confidence grows, we expand to critical workloads. This stepwise promotion ensures that even unusual failure conditions like transient API errors or unexpected dependency conflicts are handled safely.
Autonomous systems must respect the declarative rules defined in Terraform, Ansible, and Kubernetes operators. In practice, we’ve seen teams break production environments when autonomy overwrites provisioning rules unintentionally. By integrating at the state level and enforcing validations, autonomous actions complement existing scripts rather than competing with them.
Real environments always present surprises. Traffic surges, region failovers, API rate limits, or hybrid-cloud interactions can trigger failure patterns that automation alone cannot catch. We replicate these scenarios in staging, validate autonomous responses, and adjust policies accordingly. This reduces risk and builds trust in the system.
From day one, we measure cost savings, latency improvements, and reduced operational toil. In one enterprise, we observed that implementing autonomy significantly removed low-level manual interventions, while freeing engineers to focus on higher-value initiatives.
Autonomy is powerful, but it’s not omnipotent. Multi-region outages, provider API downtime, or highly complex hybrid orchestrations still require human oversight. We explicitly define these boundaries and create clear intervention points so engineers know when to step in.
Finally, autonomy improves over time. The system continuously learns from workload behavior, but we treat it as a feedback loop rather than a set-and-forget solution. Regular reviews, policy updates, and metric analysis ensure that autonomous actions evolve alongside business needs and environmental changes.
Let’s look at how a real system adapts, learns, and keeps operations running smoothly.
After struggling with scaling rules and deployment scripts long enough, it becomes clear that your team needs a system that complements human decision-making. Sedai observes, predicts, and adjusts workloads in real time, reducing manual toil while leaving engineers in control of critical decisions.
Sedai monitors workloads, scales applications, and adjusts configurations automatically. During traffic spikes or unexpected workload shifts, it reallocates compute resources to maintain performance. Companies have seen latency improvements of 30% to 75%, showing that adaptive systems handle conditions static scripts cannot.
Sedai detects early warning signs such as abnormal memory usage or unusual behaviors and remediates issues before they affect users. This preemptive handling can reduce failed customer interactions by up to 50% and improve overall system performance. Engineers familiar with traditional automation know how much time can be lost when something goes wrong: autonomy removes much of that repetitive troubleshooting.
By analyzing usage patterns and predicting resource demand, Sedai optimizes allocations and reduces wasted spend. Organizations using these strategies have reported 30% to 50% reductions in cloud costs without compromising performance or stability.
During the pandemic, Palo Alto Networks experienced a 5x growth in business and cloud workloads, creating significant operational complexity. Their SRE team managed thousands of workloads, including Kubernetes clusters and serverless environments, facing rising costs and increasing toil from manual management and static automation.
Sedai was integrated to optimize serverless and Kubernetes clusters across production and development environments. Its agents autonomously executed over 89,000 production changes with zero incidents.
The impact reported by the engineers included:
This example demonstrates how autonomous cloud management can operate reliably at scale, handling complexity that static automation cannot.
We’ve seen how rigid, rule-based automation struggles when conditions shift. Here’s the thing: autonomy, not automation alone, is the only way to manage a modern cloud safely at scale.
Moving forward, teams that adopt autonomy thoughtfully, starting with critical workflows, validating outcomes in staging, and scaling incrementally, can improve reliability, control costs, and focus engineering effort on higher-value projects. Organizations that embrace these approaches will be better positioned to handle unexpected workload spikes, hybrid and multi-cloud complexity, and rapid business growth.
If that’s the direction you want to explore, join us.
Traditional cloud automation follows static rules, while autonomous cloud management adapts in real time. It monitors changing traffic, system behavior, and deployments, making context-aware adjustments without waiting for human input.
Not reliably. Automation can handle predictable tasks, but as workloads span multiple providers or unexpected conditions arise, rule-based systems can fail. Autonomous management adds the adaptability cloud teams need for consistent performance.
By continuously analyzing workloads and predicting future resource needs, autonomous systems optimize allocation dynamically. This reduces wasted spend and ensures you’re only paying for what your cloud workloads truly require.
No. Cloud automation and autonomous platforms handle repetitive operational tasks, letting your engineers focus on higher-impact projects. It’s about augmenting your team, not replacing them.
Absolutely. Automation lays the foundation by executing predictable tasks reliably. Autonomy builds on that foundation, adapting to changes in real time, preventing failures, and improving efficiency across your cloud operations.





.svg)
.svg)




%201.svg)
%202.svg)



