
Cloud data warehouses deliver the scalability, speed, and flexibility modern teams need to handle growing data demands. They streamline integration, accelerate queries, and scale resources on demand, but managing cost and performance at scale is still a challenge. Sedai’s AI-powered automation keeps your warehouse lean and responsive, cutting waste, optimizing resources, and helping your team deliver insights without the cloud cost surprises.
Your data stack is growing fast. Queries are slowing, costs are creeping up, and your team is spending more time tuning than delivering insights. Scaling while keeping performance and costs in check is a constant challenge.
A cloud data warehouse gives you the flexibility and speed to manage large, complex datasets without the operational drag of traditional systems.
In this guide, we’ll explain what a cloud data warehouse is, how it works, and the key features that actually impact speed, scale, and cost. We’ll also explore how Sedai uses automation to keep cloud data warehouses running efficiently.
What is a Cloud Data Warehouse?
A cloud data warehouse is a managed platform for storing, processing, and analyzing massive volumes of structured and semi‑structured data, without running your own infrastructure. Unlike traditional on‑prem systems, it separates compute and storage, letting you scale each independently.
That means you can increase compute during heavy workloads, scale it down when demand drops, and only pay for what you use. Cloud data warehouses also integrate with modern analytics tools, support real‑time ingestion, and handle availability, patching, and backups for you.
The result: faster queries, predictable costs, and less manual upkeep.
6 Cloud Data Warehouse Features You Can’t Ignore
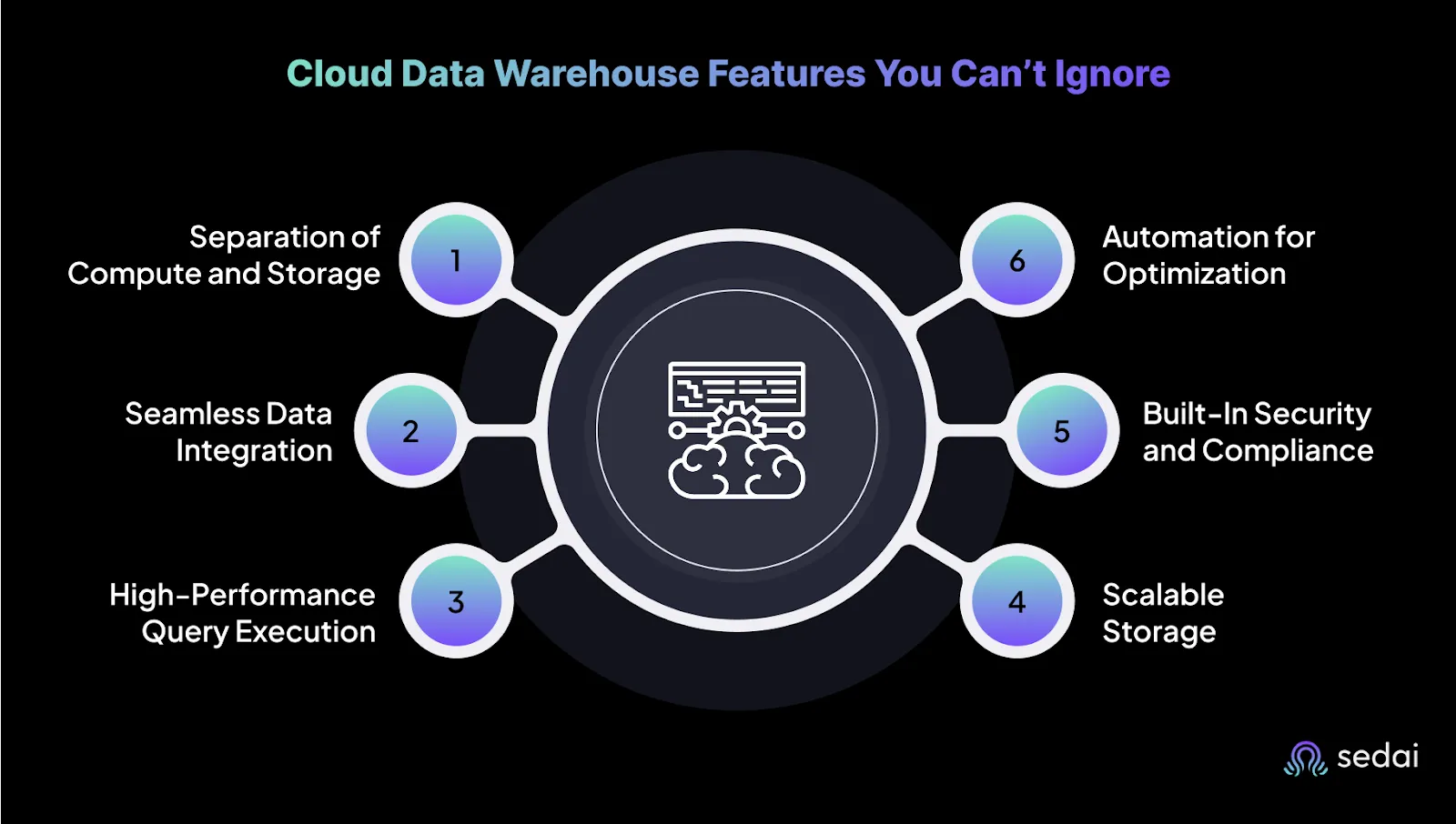
Choosing a cloud data warehouse isn’t just about picking a vendor. The right platform should make your data faster to access, easier to manage, and cheaper to run, without draining your engineering time. These six features set the best platforms apart.
1. Separation of Compute and Storage
Modern cloud data warehouses like Snowflake, Redshift RA3, and BigQuery let you scale compute and storage independently. You can boost compute for heavy analytics without duplicating storage or shutting down workloads. Storage remains persistent, while compute clusters can be paused, resized, or auto‑scaled.
Why it matters: This avoids over‑provisioning for peak loads and gives you predictable costs while handling unpredictable workloads.
2. Seamless Data Integration
Data arrives from SaaS apps, databases, logs, streams, and files — often in different formats. Cloud warehouses simplify ingestion with native connectors, streaming APIs, and support for both batch and real‑time pipelines. You can define schemas programmatically, automate ingestion jobs, and enforce granular access policies.
Why it matters: Ingest faster, reduce brittle ETL scripts, and give engineers more time to focus on analysis instead of data plumbing.
3. High‑Performance Query Execution
Columnar storage, in‑memory caching, and Massively Parallel Processing (MPP) distribute queries across nodes for faster execution. Features like query pruning and partition elimination cut scan times significantly. Multi‑cluster concurrency ensures workloads don’t block each other.
Why it matters: Reports and dashboards load quickly, even at petabyte scale, without constant query rewrites or tuning.
4. Scalable Storage
Cloud warehouses use object storage that expands automatically as your data grows. They support compression, deduplication, and tiering to keep storage costs under control. This scaling is transparent no provisioning or rebalancing required.
Why it matters: Store massive datasets without performance degradation or costly pre‑planning for capacity.
5. Built‑In Security and Compliance
Security is integrated from day one, with encryption in transit and at rest, fine‑grained RBAC, and audit logging. Leading platforms meet strict standards like HIPAA, SOC 2, GDPR, and PCI‑DSS.
Why it matters: Protect sensitive data, satisfy regulators, and avoid bolting on security as an afterthought.
6. Automation for Optimization
Modern warehouses automatically scale clusters based on query concurrency, suspend idle compute, resume on demand, and tune performance. Some integrate AI to suggest query optimizations or spot cost inefficiencies before they become problems.
Why it matters: Reduces operational toil, lowers costs, and frees engineers from routine tuning so they can focus on delivering insights.
Next, let’s break down the architecture that powers all this performance, flexibility, and scale.
Architecture of a Cloud Data Warehouse
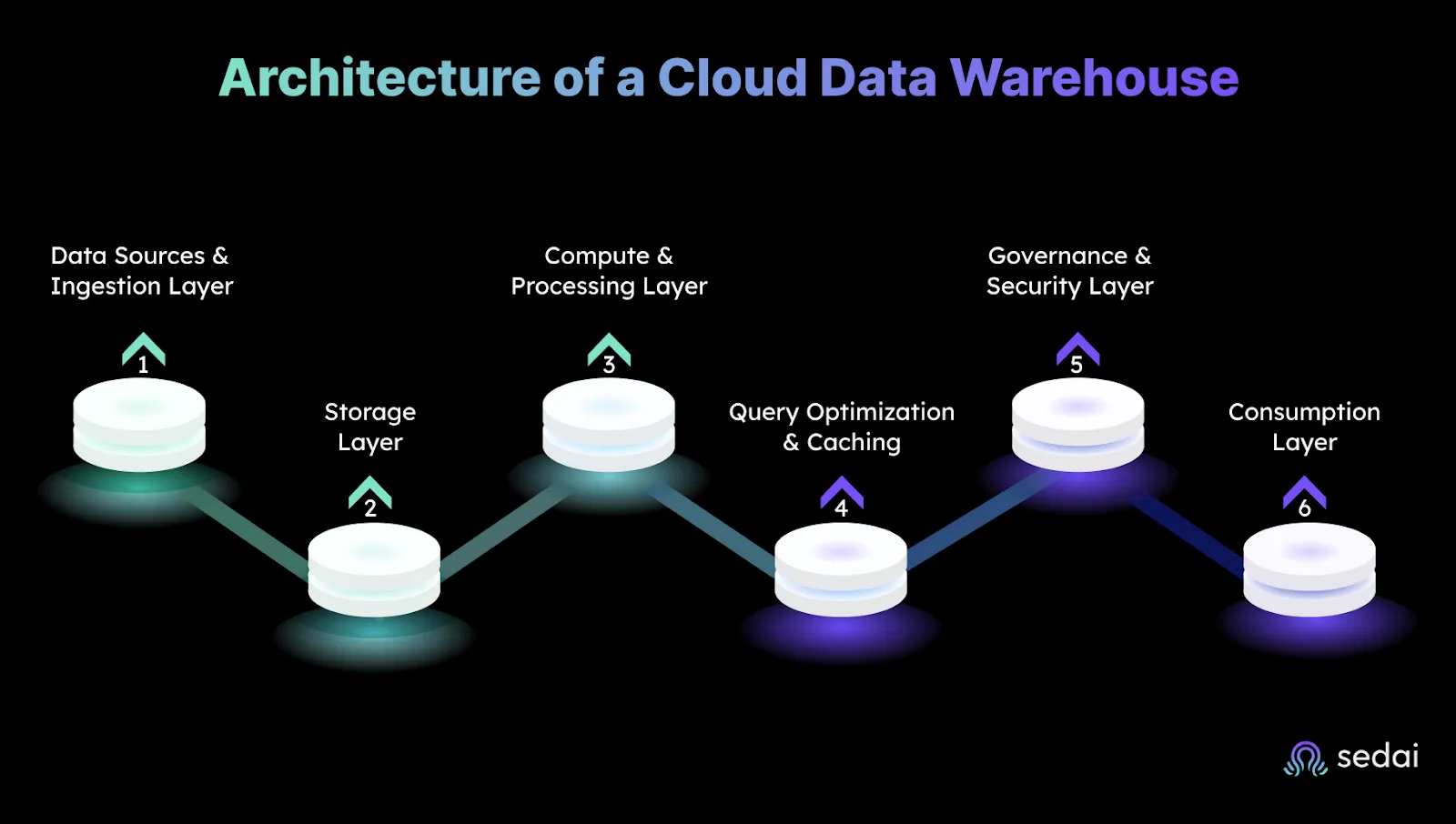
A cloud data warehouse isn’t just “a database in the cloud.” It’s a layered system built for high‑volume analytics without the capacity planning headaches of traditional setups. Understanding how these layers work helps you design for performance, scalability, and cost efficiency from day one.
1. Data Sources & Ingestion Layer
Your data comes from various sources, including transactional databases, SaaS tools, event streams, log files, and IoT devices.
- Batch ingestion for periodic loads (e.g., nightly ETL jobs).
- Streaming ingestion for real‑time updates via Kafka, Kinesis, or Pub/Sub.
- Semi‑structured support for formats like JSON, Avro, or Parquet.
Why it matters: Efficient ingestion means you’re not constantly re‑engineering brittle pipelines.
2. Storage Layer
Usually backed by scalable object storage (e.g., S3, GCS, Azure Blob).
- Stores structured and semi‑structured data.
- Separation from compute means you can expand storage without touching your query clusters.
- Compression, deduplication, and tiering to keep costs in check.
Why it matters: Your storage bill doesn’t explode just because you keep historical data for long‑term analytics.
3. Compute & Processing Layer
The muscle that runs your queries.
- Massively Parallel Processing (MPP) distributes queries across nodes for speed.
- Leader/Coordinator nodes parse queries and plan execution.
- Worker nodes scan, filter, and aggregate in parallel.
- Can scale up or down without interrupting running workloads.
Why it matters: You get predictable performance even when your analyst team all hits “run” at the same time.
4. Query Optimization & Caching
Where the warehouse earns its speed.
- Columnar storage reduces I/O by reading only relevant columns.
- Cost‑based optimizers choose the fastest execution path.
- Result caching means repeat queries return instantly.
Why it matters: Less waiting, less re‑querying, less unnecessary compute burn.
5. Governance & Security Layer
Built‑in controls to manage data access and compliance.
- Role‑based access control (RBAC).
- Encryption in transit and at rest.
- Row‑ or column‑level security for sensitive datasets.
Why it matters: Keeps you compliant without needing to bolt on third‑party solutions.
6. Consumption Layer
The interface your teams actually touch — SQL clients, BI tools, APIs, or ML pipelines.
- Connects directly to Looker, Tableau, Power BI, or custom dashboards.
- Supports real‑time data sharing without duplicating datasets.
Why it matters: Everyone works from the same, consistent data source — no shadow copies.
Traditional vs. Cloud Data Warehouse
Legacy data warehouses demand heavy upfront investment, long setup times, and constant upkeep. Cloud data warehouses flip that model, delivering elastic scale, faster performance, and less operational overhead.
Aspect | Traditional DW | Cloud DW |
|---|---|---|
Deployment | On-prem hardware, slow procurement cycles. | Fully managed, spin up in minutes. |
Scalability | Limited by physical capacity, upgrades are disruptive. | Elastic, on-demand scaling for compute and storage. |
Cost Model | High CapEx, fixed capacity even if underused. | Pay-as-you-go, no idle spend. |
Maintenance | Manual patching, backups, and tuning. | Automated updates, failover, and performance optimization. |
Performance | Degrades as data grows, tuning is manual. | Consistent query performance at petabyte scale. |
Collaboration | Restricted access, siloed teams. | Accessible from anywhere, native integration with BI/AI tools. |
Security | Slower adoption of new standards. | Built-in encryption, compliance, and granular access controls. |
Bottom line: Cloud data warehouses remove the physical and operational limits of legacy systems. You get scalability, predictable costs, and a single platform that teams can actually share, without the maintenance grind.
Next, let’s look at the common challenges and trade-offs when moving to a cloud-based warehouse model.
Cloud Data Warehousing Challenges
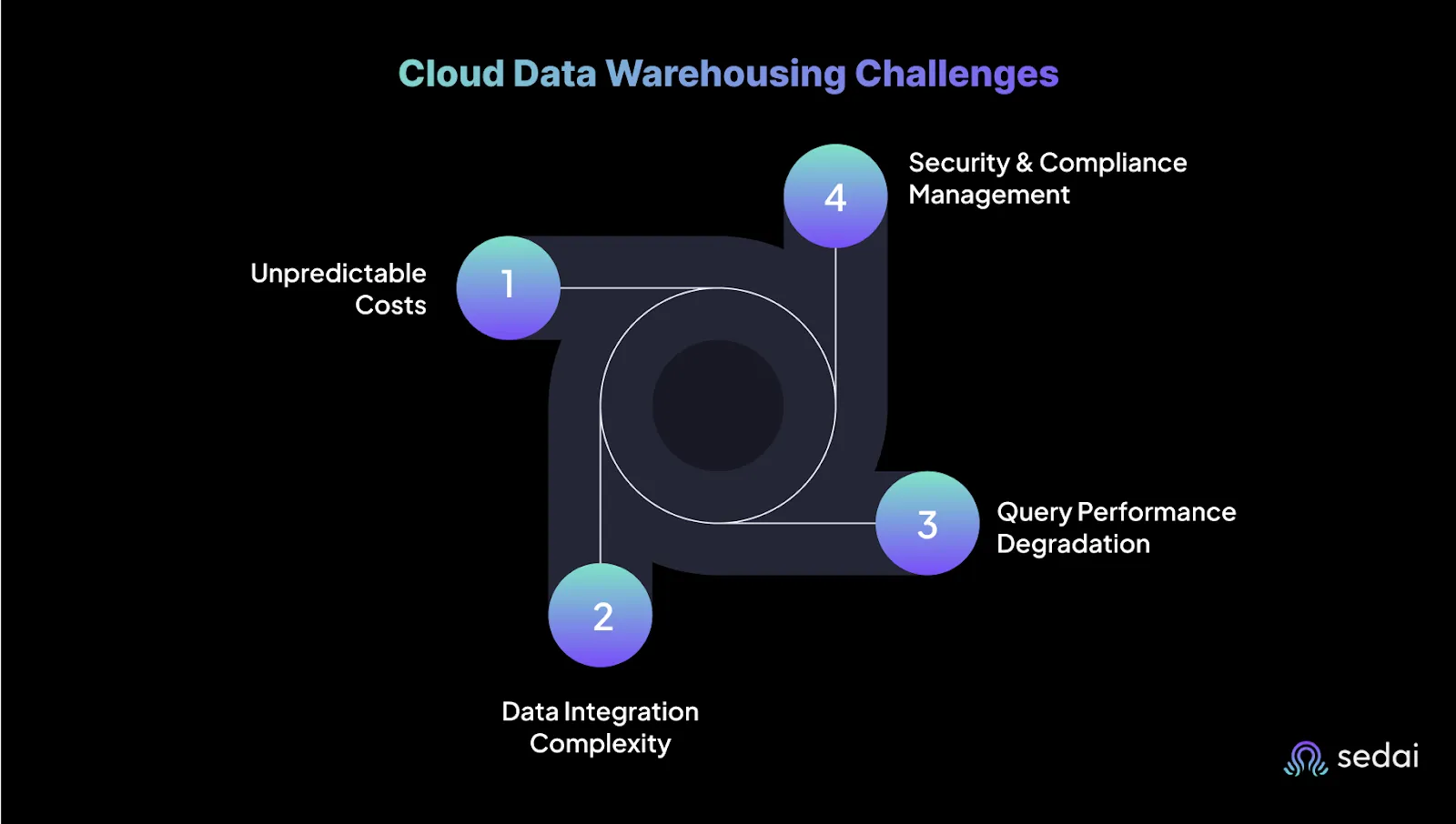
While cloud data warehouses offer scalability and flexibility, they also come with their own set of challenges:
1. Unpredictable Costs
Variable workloads and complex pricing can lead to surprise bills, especially if clusters run idle or queries aren’t optimized.
The fix: Use autosuspend/auto‑resume, monitor query performance, and set cost alerts. AI‑driven tools like Sedai can right‑size compute in real time and flag anomalies before they blow your budget.
2. Data Integration Complexity
Ingesting data from multiple sources (SaaS apps, databases, streams) introduces latency, schema drift, and reliability issues.
The fix: Standardize on ETL/ELT tools with schema‑evolution support, and schedule regular sync checks. Cloud‑native connectors or managed ingestion services reduce manual pipeline maintenance.
3. Query Performance Degradation
As datasets grow, query times can creep up, frustrating analysts and slowing down dashboards.
The fix: Partition and cluster data intelligently, use materialized views for frequent queries, and leverage automatic performance tuning features. Monitor slow queries and optimize storage formats (e.g., Parquet).
4. Security and Compliance Management
Meeting strict regulatory requirements (GDPR, HIPAA, SOC 2) can be tricky across hybrid or multi‑cloud setups.
The fix: Implement fine‑grained RBAC, encrypt data at rest and in transit, and enable audit logging. Use compliance templates offered by your cloud warehouse to standardize settings.
Suggested read: Cloud Optimization: The Ultimate Guide for Engineers
Optimize Your Cloud Data Warehouse Automatically with Sedai
Running a cloud data warehouse at scale isn’t just about speeding up queries, it’s about keeping infrastructure efficient as workloads change. Idle clusters, oversized compute, and under‑optimized storage can quietly drive up costs. Tracking and fixing all that manually wastes engineering time.
Sedai uses AI‑driven automation to handle it for you. It continuously monitors the compute, storage, and network layers powering your warehouse, right‑sizing clusters when they’re underused and scaling resources when demand changes. If query patterns shift, Sedai adjusts automatically to maintain performance without overspending.
It also flags anomalies early, like sudden spikes in usage or cost, so you can address them before they impact SLAs or budgets.
Conclusion
A modern cloud data warehouse can transform how you work, but only if you run it smart. Without the right approach, costs spiral, clusters sit idle, and your engineers spend more time fixing than innovating.
By combining the right warehouse architecture with AI‑driven automation from Sedai, you can keep compute, storage, and performance in balance without constant manual tuning. The result is faster insights, predictable costs, and a platform that scales with your business.
Join us and start running your cloud data warehouse smarter.
FAQs
1. What makes cloud data warehouses different from traditional ones?
Cloud data warehouses separate compute and storage, offer on-demand scalability, and reduce maintenance overhead compared to on-prem setups.
2. How does automation improve cloud data warehouse management?
Automation streamlines data ingestion, performance tuning, scaling, and cost control, reducing manual work and errors.
3. Can Sedai optimize costs for cloud data warehouses?
Yes, Sedai uses AI-driven automation to identify waste, optimize usage, and reduce overall cloud costs without impacting performance.
4. What are the common challenges in managing cloud data warehouses?
Challenges include managing data growth, query performance, cost overruns, and maintaining governance across multi-cloud environments.
5. How can cloud data warehouses support real-time analytics?
They use parallel processing and near real-time data ingestion to enable fast, up-to-date analytics for business decisions.