.webp%3Fv%3D2026-04-09T18%253A41%253A05.143Z&w=3840&q=75&dpl=dpl_NeFw5tgUeiJvptTeafLBGrKPURcT)

Summary
- ECS users progress through four stages of ECS optimization maturity: reactive manual optimization, proactive manual optimization, automation with rules, and autonomous AI-driven optimization.
- Reactive manual optimization requires high manual intervention and responds to issues as they arise, while proactive manual optimization uses recommendation tools for informed decisions but still involves significant manual oversight.
- Automation with rules reduces manual effort by handling routine optimization tasks based on predefined metrics, but autonomous AI-driven tools continuously learn and adapt, making sophisticated optimization decisions with minimal human intervention.
- Autonomous systems offer benefits such as shifting focus from managing templates to achieving goals, reducing the need for manual adjustments, and enhancing cost efficiency and performance through continuous optimization.
- The ECS Optimization Maturity Model helps organizations assess their current optimization capabilities and set goals to progress from basic, manual setups to advanced, AI-enhanced operations across various key areas.
From Manual to Autonomous
While each organization’s approach is different let’s consider a journey through four stages of maturity from high-touch, manual processes to sophisticated, intelligent systems that enhance performance and cost-efficiency with minimal human intervention as shown below:
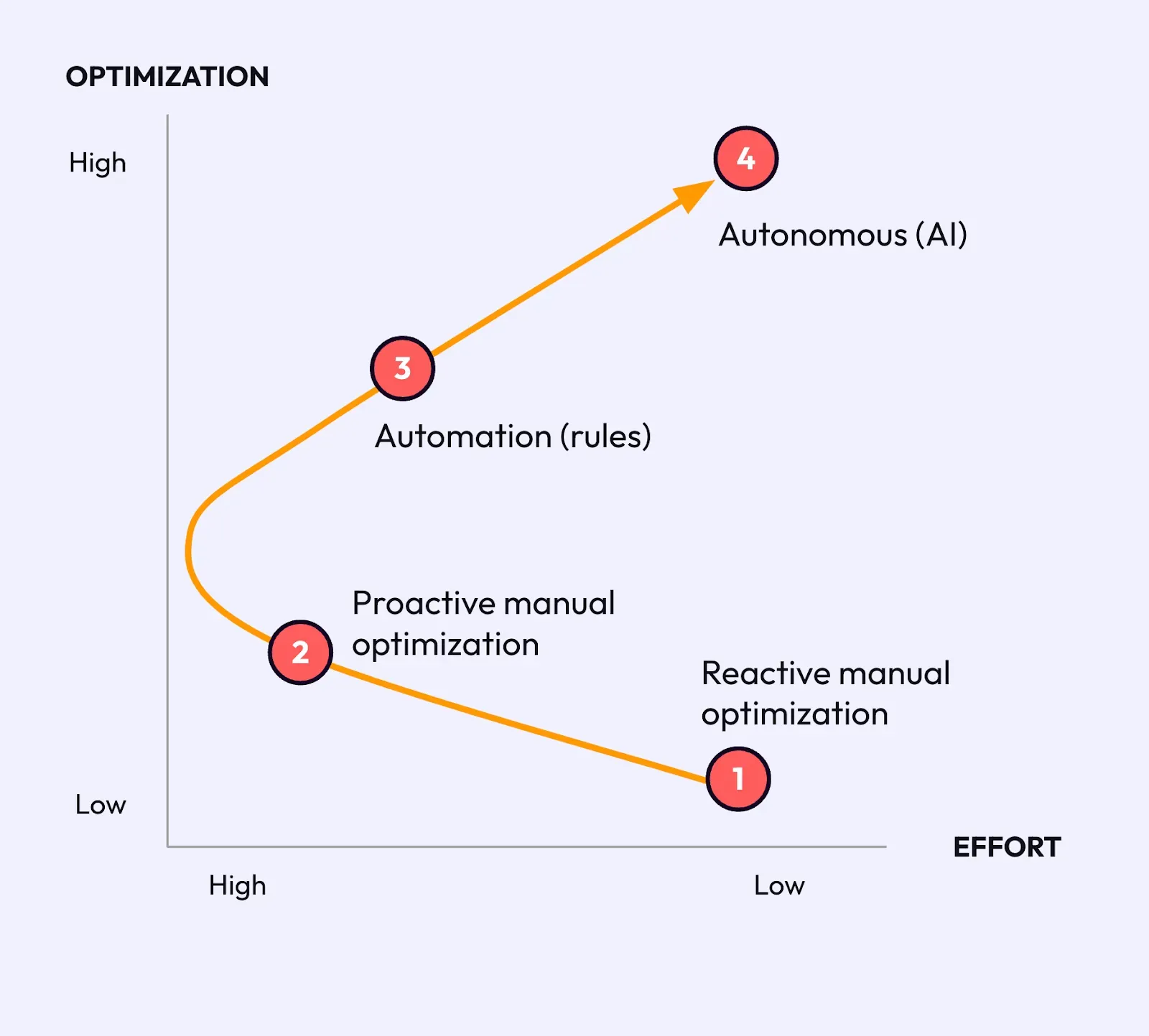
The four stages of the journey are:
- Reactive manual Optimization: The optimization journey for an Amazon ECS user typically begins with reactive manual optimization. At this initial stage, represented as the first point on the diagram, efforts are high as users are responding to issues as they arise, often after they have already impacted performance or costs. This approach requires significant manual intervention and can be inefficient, but it is a common starting point for those new to ECS.
- Proactive Manual Optimization: As users gain experience and realize the potential for greater efficiency exists, they shift towards proactive manual optimization, using recommendation tools (e.g., AWS Compute Optimizer) to inform their decisions. This stage involves a higher effort compared to reactive optimization since tools provide insights and recommendations that can only guide the user and they remain responsible for validation and execution. However, it still relies heavily on manual oversight and adjustments.
- Automation (rules): The journey progresses towards automation with rules-based tools. These tools operate on a predefined set of inputs and can handle routine optimization tasks without learning from past actions. This reduces the effort required from the user relative to manual stages but does not capture the full optimization potential.
- Autonomous (AI): the most mature stage is the use of autonomous (AI) tools. AI-driven solutions actively learn from the system's performance and user patterns over time, making increasingly sophisticated decisions to optimize ECS deployments. This not only yields higher levels of optimization but also significantly reduces the effort required from the user, as the system can adapt and improve autonomously.
- ECS cost optimization requires more than scaling policies. Book a demo to see how Sedai manages task rightsizing, spot usage, and idle resource cleanup in one platform.
Optimization in each Approach
The following table provides a detailed comparison of how each ECS optimization control — from rightsizing tasks and instances to geographical placement and autoscaling — is implemented across four key methods: Reactive Manual Optimization, Proactive Manual Optimization, Automation via rules, and Autonomous AI-driven Optimization.
Ready to take your Amazon ECS environment from manual to autonomous?
Book a Sedai demo to automate ECS optimization, reduce cloud costs, and continuously improve application performance.

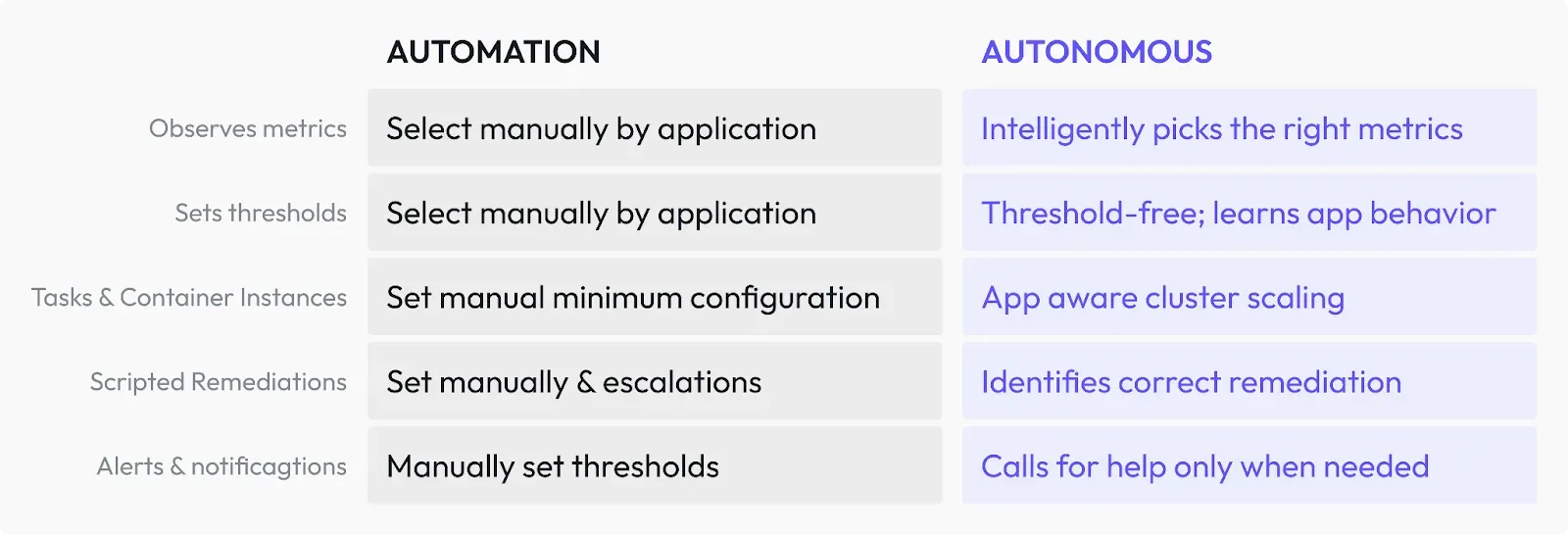
Comparing Automation to Autonomous Optimization
Let’s compare an autonomous system to traditional automated systems. Autonomous systems can undertake the following steps on its own, guided by the goals given by the user:
- Detect Problems
- Recommend Solutions
- Validate
- Execute Safely

Automation comes with challenges because it involves a lot of manual configuration. In the table below we contrast how key activities involved in optimizing ECS for cost, performance and availability differ between an automated and autonomous approach. For example, you have to manually set the thresholds and come up with the metrics that you need to monitor. However, an autonomous system continuously studies the behavior of the application and it adapts accordingly.
Below are the steps that autonomous systems use to optimize ECS environments. Imagine you have a fleet of multiple services. In the autonomous model, your topology is discovered and observed well with effective telemetry that’s being watched 24/7. That telemetry is used to understand your app behavior for each new release. That understanding of the application and how it responds is used to safely reconfigure the service. The effectiveness of that optimization is then checked and validated; and will be stopped if needed. You then learn from the change made and its effects (reinforcement learning) and then you keep repeating the loop for the service.
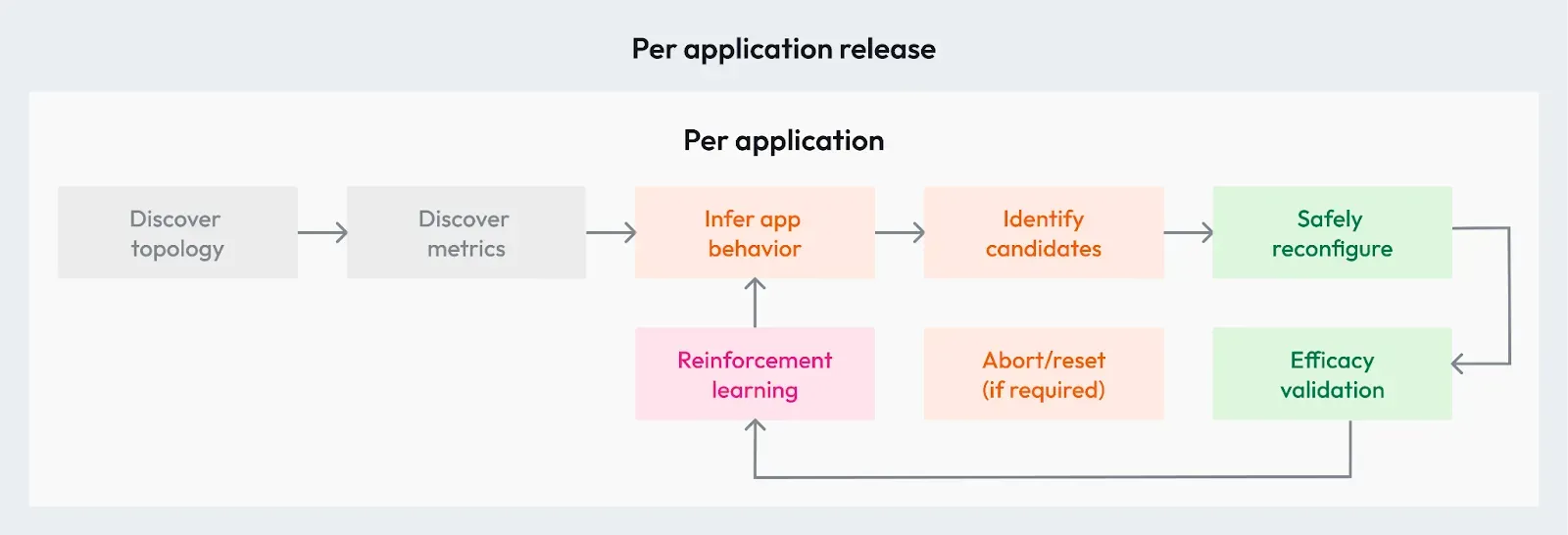
So performing these actions in the right order is the key to ensuring that we can run these services as optimized as possible from both the perspective of cost and performance.
Moving to an autonomous system allows you to shift away from managing autoscaling and service templates to focusing on goals.

If you're managing at the template level for each service, you end up with hundreds of templates that need to be modified every release. These include the individual services, service autoscalers and cluster autoscalers.
In an ideal scenario, you should avoid transferring your production runtime duties to the left. Instead, aim to elevate them to a level where an independent system can handle and optimize your runtime settings. While still requiring templates for software versions, dependencies, and other factors, the most effective approach is to shift upwards to effectively manage your runtime parameters.
Enabling Autopilot mode — where Sedai executes optimizations without requiring manual approval — is the final step in reclaiming engineering capacity from cloud operations. Book a demo to see how that final step applies to your ECS environment.
ECS Optimization Maturity Model
Below is an ECS Optimization Maturity Model that you can use to assess where your organization sits today and to set goals for upgrading your ECS optimization capabilities, taking a wider view beyond individual engineering and purchasing tactics. This table charts a clear path from basic, manual setups to advanced, AI-enhanced operations. It covers essential areas like goal-setting, engineering adjustments, smart purchasing, and more, showing you exactly how to progress from simple to state-of-the-art in managing your ECS environments effectively.
* See separate table for a more detailed view on how individual levers such as autoscaling would operate at different stages of maturity.
Control | Reactive Manual Optimization | Proactive Manual Optimization | Automation (Rules) | Autonomous (AI) |
|---|---|---|---|---|
Rightsizing of tasks | Adjust task size in response to performance issues or cost spikes. | Use AWS Compute Optimizer recommendations to adjust task size before issues occur. | Implement rules to adjust task size based on CPU / memory utilization metrics. | AI observes patterns and adjusts task size dynamically. |
Rightsizing of instances | Manually change instance sizes post-issue identification. | Schedule regular reviews to adjust instance sizes per usage reports. | Set up autoscaling policies for instance resizing based on utilization. | AI dynamically resizes instances based on real-time workload demands. |
Task placement (on instance) | Reposition tasks manually when imbalance or inefficiency is detected. | Plan task distribution based on anticipated load and capacity. | Configure placement strategies that automatically distribute tasks based on predefined rules. | AI analyzes task interdependencies and optimizes placement automatically. |
Geographic placement (region, AZ) | Change regions or AZs manually after noticing latency or cost issues. | Select optimal regions or AZs based on expected traffic geolocation and cost. | Setup automation to place tasks in regions or AZs with the best latency or cost. | AI evaluates global performance metrics to optimize geographic placement. |
Service autoscaling | Manually scale services in reaction to traffic changes. | Implement scaling policies based on predictive analysis of traffic trends. | Create CloudWatch alarms and scaling policies triggered by actual metrics. | AI predicts traffic and scales services ahead of demand fluctuations. |
Cluster autoscaling | Manually add or remove resources in the cluster as issues arise. | Regularly adjust cluster capacity based on utilization trends. | Use ECS or EC2 autoscaling with specific triggers for cluster adjustments. | AI constantly refines cluster size for optimal resource availability. |
Scheduled shutdown | Manually stop services after observing non-peak periods. | Establish a schedule based on predictable low-traffic periods; engineers expected to manually implement. | Setup CloudWatch events with Lambda to automate shutdowns on a schedule. | AI identifies patterns to optimize shutdown schedules without manual input. |
Spot instances | Switch to spot instances post hoc in an attempt to cut costs. | Evaluate and plan spot instance usage based on workloads and spot market trends. | Automate spot instance bidding and utilization based on cost thresholds. | AI manages spot instance use by predicting availability and cost savings. |
Savings plan & Reserved Instances (RI) | Purchase RIs post cost analysis to save on future use. | Analyze usage and future needs to proactively purchase Savings Plans or RIs. | Automate RI purchases based on usage patterns and financial planning. | AI projects future usage and makes purchase decisions for long-term savings. |
Area of Optimization | None | Reactive | Proactive | Automated | Autonomous |
|---|---|---|---|---|---|
Goals/SLOs | Goals are undefined or generic. | Begin setting basic SLOs based on internal benchmarks. | SLOs refined based on performance metrics and user satisfaction. | SLOs are integrated with business outcomes, adjusting for application performance and user experience. | Autonomous systems set and adjust SLOs in real-time based on deep learning of customer interactions and business impact. |
Engineering Optimization* | Manual, ad-hoc task & cluster setup with no optimization. | One off optimizations in response to problems | Defined processes with regular reviews of recommendations; autoscaling configured | Rules based optimizations run automatically | Fully autonomous optimization utilizing predictive AI for continuous and real-time adjustments. |
Purchasing Optimization (RIs, SPs)* | 100% on-demand instances | Begin using SPs or RIs following cost overrun | Traffic forecast drives SP and RI purchases | Rules used to adjust SP/RI use based on past traffic changes | AI purchases based on risk/return and traffic prediction models |
Release Management | Not monitored | Incident-driven adjustments | Systematic impact measurement of releases with defined metrics. | Rules adjust settings post-release; devs alerted to symptoms | AI updates settings, determines rollbacks, and flags code root causes |
Tagging & Metrics | Out of the box metrics only | Metrics and tags added post-incident | Golden metrics set up, tags used to differentiate workloads | Advanced tags for optimization; comprehensive metrics. | Dynamic tags as AI uncovers behavior patterns; metrics selected for predictive power |
Safety | Managed by individual engineers. | Ad-hoc responses to issues. | Developed protocols for safety. | Automated safety checks in place. | Predictive, AI-integrated safety measures. |
Roles & Processes | No defined roles. | Individual efforts, no alignment. | Cross-departmental efforts. | Clear roles, automated workflows. | Teams oversee workloads delegated to AI |
Monitoring & Reporting | Basic monitoring | Monitoring, sporadic reporting. | Business impact reports. | Thorough analytics; deeper business insights | AI-driven real-time monitoring and reporting. |