
In cloud computing, virtual machines (VMs) play a crucial role in modern infrastructure. Despite the rise of alternatives like Kubernetes and serverless platforms, many organizations still rely on VMs for their flexibility, fine-grained control, and compatibility with hybrid environments. VMs are also helpful in ensuring compliance with standards and providing better security and isolation.
However, managing a large fleet of VMs can present challenges, especially for SREs and DevOps teams. This article explores how platform teams can leverage autonomous optimization strategies to streamline VM management and improve overall operational efficiency.
Significance of VMs in Modern Infrastructure
Virtual machines (VMs) have been the foundation of cloud computing for decades. Even with the emergence of modern platforms like Kubernetes and serverless architectures, VMs remain widely used. Here’s why they continue to hold their ground in today’s cloud infrastructure:
- Flexibility and Control: VMs offer fine-grained control, which is particularly valued by large enterprises. This level of control allows companies to tailor their infrastructure to specific requirements.
- Compliance and Security: Many organizations prefer VMs because they provide strong security measures and help maintain compliance with industry standards. Their isolated nature makes them a solid choice for secure operations.
- Hybrid Cloud Compatibility: VMs seamlessly support hybrid cloud environments, making it easier for companies to move workloads between on-premise systems and the cloud. This mobility offers a practical solution for businesses transitioning to cloud-based systems.
- Cost Efficiency: VMs offer an advantage in terms of cost savings for predictable workloads. Businesses can lower their infrastructure expenses by right-sizing applications and optimizing resource usage.
- Versatility for Various Workloads: VMs are ideal for handling a wide range of workloads, from stateless web applications to stateful databases, high-performance computing, and batch processing. This versatility makes them an essential tool for diverse computing needs.
A key comparison is drawn between modern IaaS (Infrastructure as a Service) and VMs:
- IaaS (Bentley analogy): Expensive but comes with standardized practices that streamline operations.
- VMs (Land Cruiser analogy): Rugged, customizable, and versatile, capable of handling complex, tailored workloads much like a workhorse vehicle.
Having a modern IaaS might not solve all your infrastructure problems. For example, a whitepaper published by Amazon Prime highlighted the cost benefits of VMs. When they switched from a serverless and step-function-based application to one using EC2 and ECS tasks, they achieved the same quality of results but at a fraction of the cost.
Even though VMs may seem like legacy technology, they remain highly relevant. As the saying goes, "An old broom knows the dirty corners best." VMs, while traditional, offer reliability and proven performance in many enterprise scenarios.
With increased control comes the responsibility of constant tuning to achieve optimal performance. For SREs, managing fleets of VMs involves periodic tasks that can be daunting without proper tools.
The challenges include:
- Right Sizing and Capacity planning
- Provisioning and Configurations
- Hardening, Security and Compliance
- Patch Management and Cost Optimization
- Backup and Disaster Recovery
- Automation and Orchestration
- Monitoring and Diagnostics
Simplified Management of VMs on Cloud
Managing virtual machines (VMs) in the cloud makes it easier and more efficient for Site Reliability Engineers (SREs) and DevOps teams. Here are the key points highlighting this simplification:
- Hardened OS Images: Cloud marketplaces offer readily available hardened operating system images.
- Simplified Remediation: Unlike traditional environments where writing complex scripts and routines was necessary for remediation, cloud platforms provide APIs. These APIs enable straightforward actions like:
- Rebooting VMs
- Resizing resources
- Performing other necessary adjustments easily
- Built-In Tools and Insights: Modern cloud platforms have various built-in tools and matrices that provide valuable insights. These tools help SREs make informed decisions.
Over time, the management of VMs has become less complex due to these advancements.
The Role of Platform Teams in the Autonomous Journey
Platform teams are essential for guiding organizations through their autonomous journey:
- Establishing Standards: They enforce standards across VM fleets to ensure consistent performance.
- Manned-Unmanned Teaming Concept: This approach combines human oversight with automated systems to enhance operational efficiency. It allows minimal human intervention while maximizing the use of automated assets.
Manned-Unmanned Teaming in Autonomous Operations
Manned-unmanned teaming is the operational deployment of manned and unmanned assets in concert with a shared mission objective. It is actually a battlefield terminology, wherein the priority is to have a minimal number of boots on the ground while we use unmanned assets as a force multiplier to ensure mission success with the highest efficiency and least casualties.
Key Steps for the Platform Team
Here, the platform team forms the core, which enforces a certain set of standards across the fleet so that the unmanned assets can identify applications, make sense of data, find anomalies, recommend fleet optimizations, and facilitate autonomous actions. The platform team sets the framework for autonomous systems to act upon.
1. Identify App Boundaries
- Group similar computing instances performing the same task, termed as an app.
- Enable collective action if issues arise.
2. Metrics Standardization
- In heterogeneous fleets, ensure correct labeling of metrics for accurate identification.
- Different systems may use various exporters (e.g., Node Exporter for Linux, WMI Exporter for Windows).
3. Identifying the Golden Signal
Determine key telemetry signals to monitor, including:
- Latency
- Error rates
- Saturation
- Throughput
These signals help feed algorithms and machine learning systems for generating recommendations.
4. Application Discovery and Classification
- Use traffic patterns and tagging to identify applications.
- Group similar apps together.
- If instances do not fit into these criteria, classify them as orphaned apps.
5. App to Metric Mapping
- With the discovered app information, we can identify matrices and use them to run algorithms and find optimization opportunities and remediation. Establish a clear mapping between applications and their associated metrics.
The first five steps are relatively easier. Handling remediation is the last step and the toughest one.
6. Handling Remediations
The final step of remediation is the most challenging. If the recommendation system proposes a remediation action, it must follow a sequence of steps for safe execution in the customer environment.
Steps for Safe Remediation Action
Here are some steps for safe remediation action:
- Action Assessment: If a recommendation system proposes a remediation action, it must first determine if the action can be safely performed on the application without risk. If there is a green signal, the process continues.
- Timing Consideration: Next, assessing whether it is the right time to apply the action or if there is a preferred time for executing it on the application is essential. If both the first two steps are approved, the action can proceed.
- Action Execution: If both previous steps are clear, execute the action.
- Health Check: After executing the action, the application's health needs to be evaluated. This step is crucial for ensuring that the application remains functional post-remediation.
- Efficacy Validation: The final step involves validating the operation's efficacy. This is vital as it allows us to close the learning loop and utilize this information for future actions.
Sedai addresses the challenges SREs face using cloud and custom APIs to identify and discover infrastructure components. The inference engine employs this information to build a topology. With the topology, we can deduce the application. Our metric exporter collects data from all monitoring providers, and using the application and metrics data, Sedai’s machine learning algorithms generate remediations and optimization opportunities.
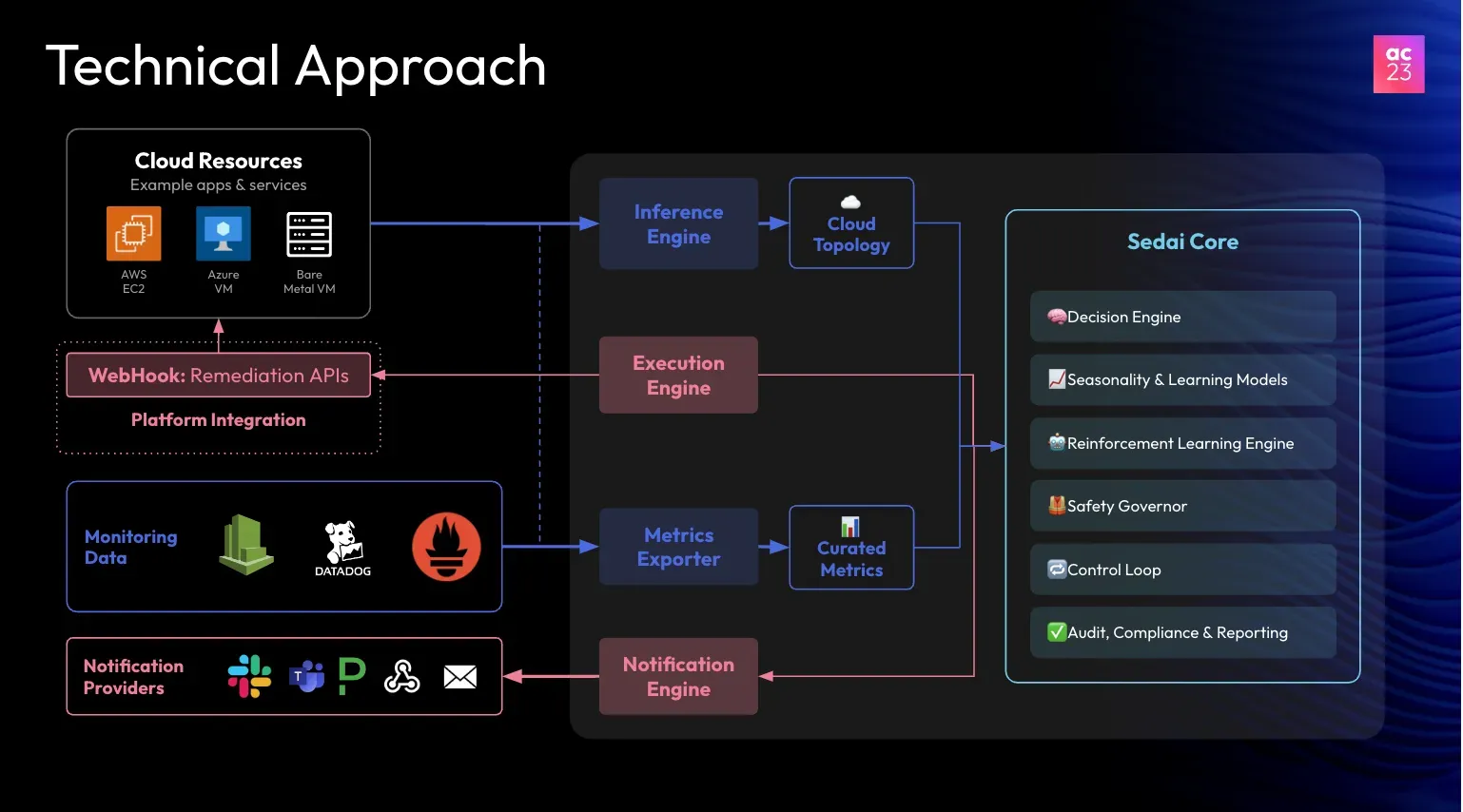
This information is then handed off to the execution engine, which carries out the final leg of the process. The execution engine must be carefully and cohesively integrated into the platform to effectively utilize remediation APIs for executing actions in the cloud.
Autonomous Actions for VM Availability and Optimization
Autonomous actions for availability and optimization in virtual machines (VMs) involve executing autonomous remediations and also optimizing performance and cost.
- Autonomous Remediations: Execute remediations based on anomalies detected in latency, errors, and custom metrics.
- Performance Optimization: Recommend optimal auto-scaling configurations and vertical resizing for applications based on predicted saturation metric patterns.
- Cost Optimization: Based on predicted traffic, identify the appropriate sizing required for applications. Use seasonal information to shut down development and QA instances selectively.
You can run autonomous remediations based on anomalies detected on latency error and custom matrices. When it comes to performance or cost optimization, you need to look at the provisioning state of the application.
- Over-Provisioned Applications: In cases of over-provisioning, costs can be saved by resizing the application.
- Under-Provisioned Applications: If an application is under-provisioned, it is necessary to assess the performance impacts and resize it accordingly to remedy any problems.
- Selective Shutdown: In certain scenarios, selective shutdown based on the seasonality of non-usage of the VMs can also be implemented.
Sedai VM Optimization
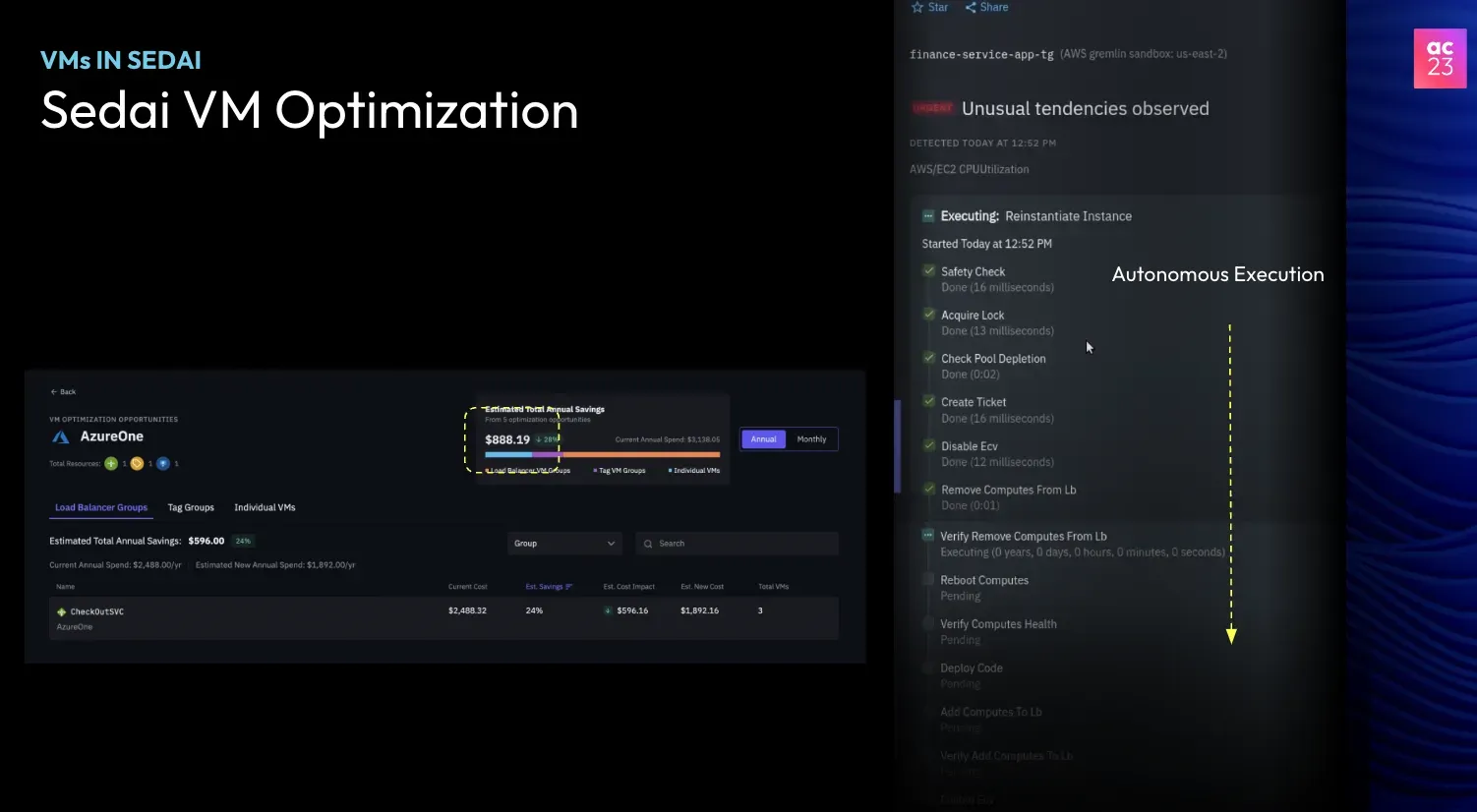
In the Sedai application, the VM optimization page showcases optimization opportunities for specific accounts. It displays autonomous execution undertaken for VM-based applications, demonstrating meticulous attention to detail in each step.
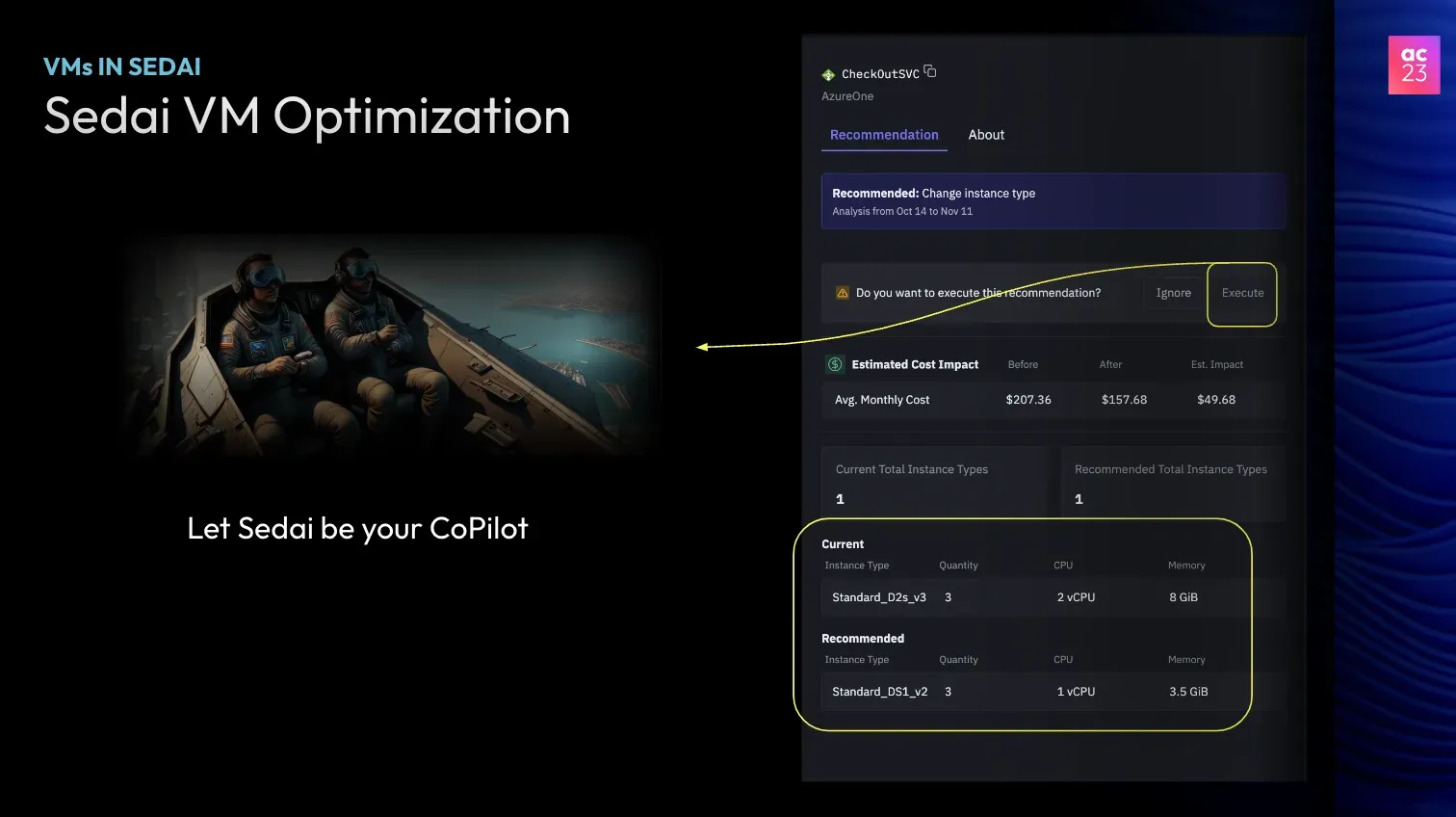
In environments with complex setups, Sedai provides autonomous systems with a higher degree of freedom. If desired, control can be handed over to a Site Reliability Engineer (SRE) for collaborative execution of autonomous actions. This aspect of teamwork in execution is referred to as manned and unmanned teaming.
Addressing non-standard setups in VM-based applications involves identifying multiple applications deployed on a single VM. This is done by examining the ports used and deriving metrics from the gathered information. While discovering application data is relatively easier, handling the operations can be more complex.
The autonomous system ensures that the right time for executing operations is considered, particularly for multiple applications running on the same VM. It is safer to schedule operations during low-traffic periods or planned downtimes.
Support for VM-Based Applications in Clouds
Sedai does support VM-based applications across various cloud platforms. Currently, we provide support for:
- AWS: Full support for virtual machines on Amazon Web Services.
- Azure: Comprehensive support for VM-based applications on Microsoft Azure.
- VMware: Support for enterprise customers using VMware.
- On-Premise: Supported through custom integrations.
Sedai plans to broaden its product rollout for Google Cloud Platform (GCP), expected by the end of Q4. This multi-cloud support ensures users can leverage Sedai's capabilities regardless of their cloud environment.
Unlock the Future of Autonomous VM Management with Sedai
In cloud computing, Sedai stands at the forefront of optimizing VM management through its innovative autonomous systems. By simplifying the complexities of virtual machine operations, Sedai enables businesses to enhance performance, reduce costs, and ensure robust application availability.
With support for major cloud platforms like AWS, Azure, and VMware, along with plans for GCP, Sedai provides a comprehensive solution tailored to meet the diverse needs of enterprises.
Ready to optimize your VM management and elevate your cloud operations? Discover how Sedai can transform your infrastructure with autonomous solutions tailored to your business needs.
Book a demo today to learn more about our offerings and get started on your journey to enhanced efficiency and effectiveness in cloud computing.